![]() [main]Notes on TeXmacs
[main]Notes on TeXmacs
![]() [main]Notes on TeXmacs
[main]Notes on TeXmacs
[6.1.2021]
In TeXmacs we use GNU Guile version 1.8 as embedded Scheme interpreter. Lately, this has been a source of problems, mostly related to packaging. On one hand Guile 1.8 is no more supported in standard Linux distributions. This implies that we have either to ship Guile in our codebase or maintain a private repository for Guile 1.8. On the other hand more recent versions of Guile compile the sources to bytecode and introduce a separated expansion and evaluation phases which break part of our codebase. Moreover while Guile 2 has a fine compiler, it has been for some time quite slow in interpreting code and only recently with the introduction of a JIT compiler in Guile 3 the interpreted code runs as fast as in Guile 1.8. Finally we have some difficulties in compiling Guile 2 on Windows and Guile 3 seems not yet be supported there. The GNU Lilypond project seems to have run into similar issues with Guile and they also remained with Guile 1.8.8 (see here).
This situation is not very nice and we would like to move forward and remove these problems. Therefore we are currently evaluating various possible strategies to evolve the way we run Scheme code within TeXmacs. The following are the criteria we want to take into account.
We use Scheme as an extension language to run on top of the GUI and the typesetting code in order to implement the dynamical and programmable UI. Additionally, if the implementation speed allows we can shift some of the conversion code in Scheme. We have C++ at our disposal anyway so we can always drop there for speed-critical tasks, but is nicer to be able to write Scheme code instead of C++.
TeXmacs already needs a huge library like
We need to be cross-platform so we would like to minimize the problem related to porting the Scheme implementation on the various OSs and architectures.
Guile 1.8 speed is OK so far. However we cannot loose performance (especially at boot time and for standard operations like moving the cursor around). We could even hope to gain some speed by using an alternative implementation.
TeXmacs do not currently use Unicode for its internal string representations but a custom formate (TeXmacs universal representation), so marshaling data to Unicode-aware Schemes is a mildly issue for us.
As for the available alternatives, the situation so far is the following.
An easy choice would be to just integrate in our codebase the sources of Guile 1.8 (which is not more maintained) in TeXmacs. This would not require changes to our scheme code. However the packaging problems remains, moreover there are large portions of the library we do not use.
We can go with Guile 3 and get the nice speed improvement wrt. 1.8. See here for some updates on the development of Guile. This will require more or less extensive changes to our Scheme code. These changes are been implemented in a git development branch and so far the situation seems promising. One drawback of this choice is the fact that support for platforms like Windows is not the primary goal of the Guile developers (as far as we understand) and also that Guile is become a large standalone scheme with many library dependencies, far from its origin as extension language. So the benefits of the compiler should be weighted against the difficulty of packaging and also the stability of the cross-platform support. Also Guile 2/3 has encoding-aware strings which poses a (small) problem for us and would require some hackery to get around.
An attractive option is to switch to another small, embeddable
Scheme interpreter like
A radical alternative is to consider the embedding of a full-fledged
Scheme compiler. By looking at the multitude of Scheme
implementations around we singled out
The development branches of TeXmacs for Guile 3 and S7 can be found here:
We performed some test of these alternative implementations to help us make a preliminary picture. We used some standard R7RS benchmarks found here and we got the results shown below on a MacBook Air (2019). They show that S7 is consistently the fastest interpreter wrt. Chibi or Guile 1.8. We also see that, as expected, Chez is among the fastest implementations available with consistent timings all across the benchmarks.
We currently have working implementations of TeXmacs with Guile 1.8, S7 and Guile 3.0.4 and what we see from preliminary tests is that boot time of S7 is comparable to that of Guile 3.0.4 (0.4 sec) and half of that of Guile 1.8 (0.8 sec). Also compile the full manual require the roughly the same time to all the three implementations (~15 sec). We would need to consider more intensive tests to discriminate the tradeoffs in performances of the various choices.
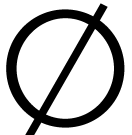
Here are the results of the R7RS benchmarks. The symbol ∅ denotes that the program exceeded a conventional time limit and was interrupted.
test |
s7 |
chibi 0.9.1 |
chez 9.5.1 |
guile 1.8.8 |
guile 3.0.4 |
browse:2000 |
24.27 |
|
0.84 |
76.63 |
12.06 |
deriv:10000000 |
25.19 |
97.11 |
1.15 |
67.27 |
18.58 |
destruc:600:50:4000 |
52.08 |
94.90 |
2.21 |
|
7.14 |
diviter:1000:1000000 |
9.69 |
55.88 |
1.81 |
82.75 |
15.45 |
divrec:1000:1000000 |
11.80 |
50.91 |
2.19 |
82.04 |
17.41 |
puzzle:1000 |
27.72 |
270.98 |
1.66 |
221.49 |
18.09 |
triangl:22:1:50 |
33.93 |
110.86 |
1.91 |
107.15 |
8.52 |
tak:40:20:11:1 |
12.93 |
55.19 |
1.66 |
134.21 |
4.76 |
takl:40:20:12:1 |
20.97 |
|
3.71 |
|
9.46 |
ntakl:40:20:12:1 |
17.07 |
95.98 |
3.65 |
|
9.52 |
cpstak:40:20:11:1 |
103.36 |
222.13 |
4.21 |
258.62 |
59.44 |
ctak:32:16:8:1 |
44.14 |
|
0.96 |
|
|
fib:40:5 |
10.22 |
96.25 |
3.63 |
236.65 |
12.09 |
fibc:30:10 |
25.80 |
|
0.71 |
|
|
fibfp:35.0:10 |
1.89 |
42.79 |
3.18 |
56.26 |
22.00 |
sum:10000:200000 |
6.64 |
99.79 |
3.59 |
|
6.87 |
sumfp:1000000.0:500 |
2.50 |
85.36 |
4.25 |
111.78 |
42.06 |
fft:65536:100 |
32.20 |
69.76 |
3.32 |
|
7.69 |
mbrot:75:1000 |
24.40 |
209.51 |
5.39 |
|
50.09 |
mbrotZ:75:1000 |
18.56 |
|
9.26 |
|
67.01 |
nucleic:50 |
19.95 |
79.05 |
2.59 |
69.32 |
15.35 |
pi |
– |
|
0.60 |
|
0.56 |
pnpoly:1000000 |
17.98 |
253.84 |
4.73 |
|
24.89 |
ray:50 |
20.46 |
119.63 |
2.83 |
|
18.51 |
simplex:1000000 |
46.34 |
182.76 |
2.34 |
|
13.90 |
ack:3:12:2 |
10.57 |
74.51 |
3.12 |
|
8.41 |
array1:1000000:500 |
11.48 |
64.18 |
8.16 |
138.45 |
9.24 |
string:500000:100 |
1.71 |
6.34 |
6.54 |
1.81 |
1.87 |
sum1:25 |
0.47 |
121.78 |
2.02 |
1.71 |
4.43 |
cat:50 |
1.19 |
70.95 |
2.69 |
|
28.40 |
tail:50 |
1.19 |
11.21 |
3.57 |
|
9.82 |
wc:inputs/bib:50 |
8.27 |
|
1.76 |
73.34 |
16.96 |
read1:2500 |
0.41 |
281.23 |
1.28 |
2.69 |
5.80 |
compiler:2000 |
41.16 |
115.83 |
2.99 |
|
5.15 |
conform:500 |
51.03 |
199.42 |
2.10 |
|
10.51 |
dynamic:500 |
22.74 |
288.25 |
4.01 |
71.60 |
7.37 |
earley |
|
|
5.03 |
|
9.49 |
graphs:7:3 |
127.61 |
|
2.27 |
|
23.03 |
lattice:44:10 |
139.28 |
|
3.91 |
|
15.94 |
matrix:5:5:2500 |
72.07 |
214.16 |
1.63 |
|
9.88 |
maze:20:7:10000 |
23.26 |
84.15 |
1.66 |
|
4.70 |
mazefun:11:11:10000 |
19.51 |
122.02 |
2.86 |
128.66 |
9.66 |
nqueens:13:10 |
55.11 |
165.25 |
4.99 |
|
19.37 |
paraffins:23:10 |
31.42 |
|
5.97 |
|
4.25 |
parsing:2500 |
39.44 |
|
3.35 |
|
10.69 |
peval:2000 |
29.68 |
177.10 |
2.05 |
107.05 |
15.64 |
primes:1000:10000 |
7.73 |
21.08 |
2.64 |
43.73 |
7.52 |
quicksort:10000:2500 |
94.00 |
|
3.90 |
|
13.25 |
scheme:100000 |
71.46 |
154.36 |
2.55 |
|
15.14 |
slatex:500 |
32.07 |
173.60 |
3.73 |
43.82 |
45.05 |
chudnovsky |
– |
|
0.32 |
|
0.31 |
nboyer:5:1 |
39.27 |
41.54 |
3.95 |
142.86 |
5.10 |
sboyer:5:1 |
31.54 |
39.14 |
1.30 |
155.49 |
4.76 |
gcbench:20:1 |
20.54 |
|
1.87 |
|
3.51 |
mperm:20:10:2:1 |
173.33 |
659.14 |
13.33 |
|
10.65 |
equal:100:8:1000:2000:5000 |
0.78 |
54.11 |
0.99 |
|
|
bv2string:1000:1000:100 |
10.78 |
11.17 |
2.47 |
|
4.49 |
[8.1.2021]
Some more benchmarks. Populating the autocompletion tree (i.e. pressing Tab in a Scheme session within TeXmacs)
|
symbols |
time (msec) |
guile 1.8.8 |
8639 |
686 |
guile 3.0.5 |
10300 |
217 |
S7 |
7360 |
255 |
[12.4.2021]
Another interesting system is femtolisp which is currenlty in use within Julia for the initial stage of parsing and syntactic elaboration. It is a small lisp with lexical scoping and bytecode interpreter. The benchmarks have been updated to include it. S7 seems still faster on average.
test |
femtolisp |
s7 |
chibi 0.9.1 |
chez 9.5.1 |
guile 1.8.8 |
guile 3.0.4 |
browse:2000 |
|
24.27 |
|
0.84 |
76.63 |
12.06 |
deriv:10000000 |
11.56 |
25.19 |
97.11 |
1.15 |
67.27 |
18.58 |
destruc:600:50:4000 |
27.05 |
52.08 |
94.90 |
2.21 |
|
7.14 |
diviter:1000:1000000 |
20.02 |
9.69 |
55.88 |
1.81 |
82.75 |
15.45 |
divrec:1000:1000000 |
20.64 |
11.80 |
50.91 |
2.19 |
82.04 |
17.41 |
puzzle:1000 |
74.62 |
27.72 |
270.98 |
1.66 |
221.49 |
18.09 |
triangl:22:1:50 |
34.29 |
33.93 |
110.86 |
1.91 |
107.15 |
8.52 |
tak:40:20:11:1 |
24.78 |
12.93 |
55.19 |
1.66 |
134.21 |
4.76 |
takl:40:20:12:1 |
74.92 |
20.97 |
|
3.71 |
|
9.46 |
ntakl:40:20:12:1 |
60.71 |
17.07 |
95.98 |
3.65 |
|
9.52 |
cpstak:40:20:11:1 |
49.13 |
103.36 |
222.13 |
4.21 |
258.62 |
59.44 |
ctak:32:16:8:1 |
101.5 |
44.14 |
|
0.96 |
|
|
fib:40:5 |
46.50 |
10.22 |
96.25 |
3.63 |
236.65 |
12.09 |
fibc:30:10 |
64.58 |
25.80 |
|
0.71 |
|
|
fibfp:35.0:10 |
45.34 |
1.89 |
42.79 |
3.18 |
56.26 |
22.00 |
sum:10000:200000 |
55.43 |
6.64 |
99.79 |
3.59 |
|
6.87 |
sumfp:1000000.0:500 |
32.92 |
2.50 |
85.36 |
4.25 |
111.78 |
42.06 |
fft:65536:100 |
36.87 |
32.20 |
69.76 |
3.32 |
|
7.69 |
mbrot:75:1000 |
|
24.40 |
209.51 |
5.39 |
|
50.09 |
mbrotZ:75:1000 |
|
18.56 |
|
9.26 |
|
67.01 |
nucleic:50 |
50.83 |
19.95 |
79.05 |
2.59 |
69.32 |
15.35 |
pi |
|
– |
|
0.60 |
|
0.56 |
pnpoly:1000000 |
107.00 |
17.98 |
253.84 |
4.73 |
|
24.89 |
ray:50 |
27.11 |
20.46 |
119.63 |
2.83 |
|
18.51 |
simplex:1000000 |
85.77 |
46.34 |
182.76 |
2.34 |
|
13.90 |
ack:3:12:2 |
44.28 |
10.57 |
74.51 |
3.12 |
|
8.41 |
array1:1000000:500 |
59.10 |
11.48 |
64.18 |
8.16 |
138.45 |
9.24 |
string:500000:100 |
6.30 |
1.71 |
6.34 |
6.54 |
1.81 |
1.87 |
sum1:25 |
0.73 |
0.47 |
121.78 |
2.02 |
1.71 |
4.43 |
cat:50 |
28.36 |
1.19 |
70.95 |
2.69 |
|
28.40 |
tail:50 |
1.08 |
1.19 |
11.21 |
3.57 |
|
9.82 |
wc:inputs/bib:50 |
39.55 |
8.27 |
|
1.76 |
73.34 |
16.96 |
read1:2500 |
1.53 |
0.41 |
281.23 |
1.28 |
2.69 |
5.80 |
compiler:2000 |
|
41.16 |
115.83 |
2.99 |
|
5.15 |
conform:500 |
47.04 |
51.03 |
199.42 |
2.10 |
|
10.51 |
dynamic:500 |
|
22.74 |
288.25 |
4.01 |
71.60 |
7.37 |
earley |
35.82 |
|
|
5.03 |
|
9.49 |
graphs:7:3 |
99.22 |
127.61 |
|
2.27 |
|
23.03 |
lattice:44:10 |
135.43 |
139.28 |
|
3.91 |
|
15.94 |
matrix:5:5:2500 |
45.10 |
72.07 |
214.16 |
1.63 |
|
9.88 |
maze:20:7:10000 |
|
23.26 |
84.15 |
1.66 |
|
4.70 |
mazefun:11:11:10000 |
28.50 |
19.51 |
122.02 |
2.86 |
128.66 |
9.66 |
nqueens:13:10 |
63.33 |
55.11 |
165.25 |
4.99 |
|
19.37 |
paraffins:23:10 |
6.12 |
31.42 |
|
5.97 |
|
4.25 |
parsing:2500 |
|
39.44 |
|
3.35 |
|
10.69 |
peval:2000 |
32.29 |
29.68 |
177.10 |
2.05 |
107.05 |
15.64 |
primes:1000:10000 |
13.52 |
7.73 |
21.08 |
2.64 |
43.73 |
7.52 |
quicksort:10000:2500 |
119.74 |
94.00 |
|
3.90 |
|
13.25 |
scheme:100000 |
|
71.46 |
154.36 |
2.55 |
|
15.14 |
slatex:500 |
|
32.07 |
173.60 |
3.73 |
43.82 |
45.05 |
chudnovsky |
|
– |
|
0.32 |
|
0.31 |
nboyer:5:1 |
12.48 |
39.27 |
41.54 |
3.95 |
142.86 |
5.10 |
sboyer:5:1 |
15.42 |
31.54 |
39.14 |
1.30 |
155.49 |
4.76 |
gcbench:20:1 |
|
20.54 |
|
1.87 |
|
3.51 |
mperm:20:10:2:1 |
|
173.33 |
659.14 |
13.33 |
|
10.65 |
equal:100:8:1000:2000:5000 |
3.61 |
0.78 |
54.11 |
0.99 |
|
|
bv2string:1000:1000:100 |
10.21 |
10.78 |
11.17 |
2.47 |
|
4.49 |