![]() [main]Notes on TeXmacs
[main]Notes on TeXmacs
![]() [main]Notes on TeXmacs
[main]Notes on TeXmacs
[Version 1.0 of 3.1.2025. By @mgubi]
This document describes TeXmacs fonts handling. We describe the state of affairs as per svn revision r14561 (December 2024, TeXmacs 2.14+). Parts of the general overview of fonts in TeXmacs are extracted, for reference, from the official documentation and from the paper “Mathematical font art” by Joris van der Hoeven.
Philosophically speaking, we think that a font should be characterized by the following two essential properties:
A font associates graphical meanings to words. The words can always be represented by strings.
The way this association takes place is coherent as a function of the word.
By a word, we either mean a word in a natural language, or a sequence of mathematical, technical or artistic symbols. This way of viewing fonts has several advantages:
A font may take care of kerning and ligatures.
A font may consist of several “physical fonts”, which are somehow merged together.
A font might in principle automatically build very complicated glyphs like hieroglyphs or large delimiters from words in a well chosen encoding.
A font is an irreducible and persistent entity, not a bunch of commands whose actions may depend on some environment.
Notice finally that the “graphical meaning” of a word might be more than just a bitmap: it might also contain some information about a logical bounding box, appropriate places for scripts, etc. Similarly, the “coherence of the association” should be interpreted in its broadest sense: the font might contain additional information for the global typesetting of the words on a page, like the recommended distance between lines, the height of a fraction bar, etc.
Fonts are usually made up from glyphs like “x”,
“ffi”, “ ”,
“
”,
“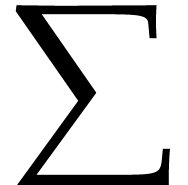 ”,
etc. When rendering a string, the string is decomposed into
glyphs so as to take into account ligatures (like fi, fl, ff, ffi, ffl).
Next, the individual glyphs are positioned while taking into account
kerning information (in “xo” the “o” character
is slightly shifted to the left so as to take profit out of the hole in
the “x”). In the case of mathematical fonts, TeXmacs also
provides a coherent rendering for resizable characters, like the large
brackets in
”,
etc. When rendering a string, the string is decomposed into
glyphs so as to take into account ligatures (like fi, fl, ff, ffi, ffl).
Next, the individual glyphs are positioned while taking into account
kerning information (in “xo” the “o” character
is slightly shifted to the left so as to take profit out of the hole in
the “x”). In the case of mathematical fonts, TeXmacs also
provides a coherent rendering for resizable characters, like the large
brackets in
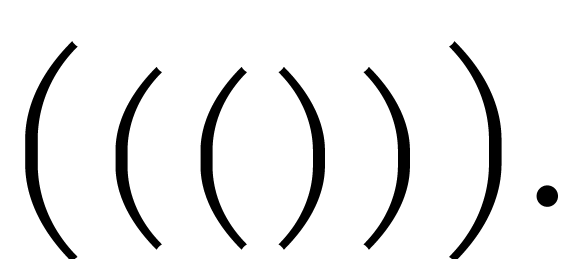
All text strings in TeXmacs consist of sequences of either specific or universal symbols. A specific symbol is a character, different from '\0', '<' and '>'. Its meaning may depend on the particular font which is being used. A universal symbol is a string starting with '<', followed by an arbitrary sequence of characters different from '\0', '<' and '>', and ending with '>'. The meaning of universal characters does not depend on the particular font which is used, but different fonts may render them in a different way.
Universal symbols can also be used to represent mathematical symbols of variable sizes like large brackets. The point here is that the shapes of such symbols depend on certain size parameters, which can not conveniently be thought of as font parameters. This problem is solved by letting the extra parameters be part of the symbol. For instance, "<left-(-1>" would be usual bracket and "<left-(-2>" a slightly larger one.
Font properties may be controlled globally for the whole document in
A font family is a family of fonts with different characteristics (like font weight, slant, etc.), but with a globally consistent rendering. One also says that the fonts in a font family “mix well together”. For instance, the standard roman font and its bold and italic variants mix well together, but the computer modern roman font and the Avant Garde font do not.
Remark
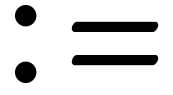 roman
roman
These variables control the main name of the font, also called the font family. For instance:
Similarly, TeXmacs supports various mathematical fonts: [Does not render correctly]
Roman: 
Adobe: 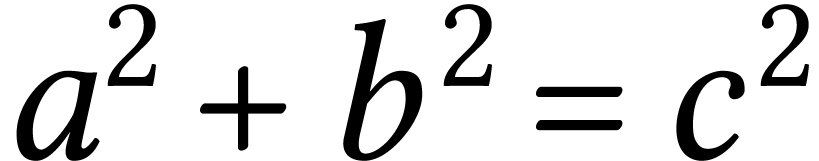
New roman: 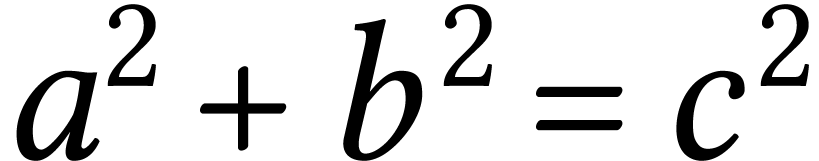
Concrete: 
Most fonts only implement a subset of all Unicode glyphs. Sometimes, the user might wish to combine several fonts to cover a larger subset. For instance, when specifying roman,IPAMincho or cjk=IPAMincho,roman as the font name, ordinary text and mathematics will be typeset using the default roman font, whereas Chinese text will use the IPAMincho font. Similarly, when specifying math=Stix,roman as the font name, ordinary text will be typeset using the default roman font, but mathematical formulas using the Stix font.
rm
This variable selects a variant of the major font, like a sans serif font, a typewriter font, and so on. As explained above, variants of a given font are designed to mix well together. Physically speaking, many fonts do not come with all possible variants (sans serif, typewriter, etc.), in which case TeXmacs tries to fall back on a suitable alternative font.
Typical variants for text fonts are rm (roman), tt (typewriter) and ss (sans serif):
roman, typewriter and
Sans serif formula: 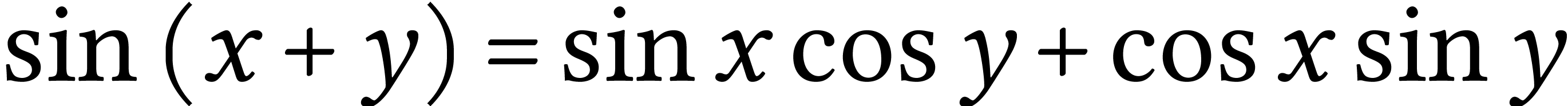
medium
The font series determines the weight of the font. Most fonts only provide regular and bold font weights. Some fonts also provide light as a possible value.
light, medium, bold
right
The font shape determines other characters of a font, like its slant, whether we use small capitals, whether it is condensed, and so on. For instance,
The base font size is specified in pt units and is usually invariant throughout the document. Usually, the base font size is 9pt, 10pt, 11pt or 12pt. Other font sizes are usually obtained by changing the magnification or the relative font-size.
9pt, 10pt, 11pt, 12pt
The real font size is obtained by multiplying the font-base-size
by the font-size multiplier. The following
standard font sizes are available from
|
||||||||||||||||||||
From a mathematical point of view, the multipliers are in a geometric
progression with factor 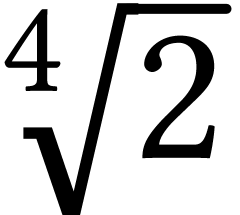 .
Notice that the font size is also affected by the index
level.
.
Notice that the font size is also affected by the index
level.
600
The rendering quality of raster fonts (also called Type 3 fonts), such
as the fonts generated by the
For more details see the paper, J. van der Hoeven, “Mathematical font art” available at https://www.texmacs.org/joris/fontart/fontart-abs.html.
The typesetting of technical documents require a large set of glyphs which are typically not available in standard fonts. TeXmacs' general strategy for turning existing fonts into full fledged mathematical font families is to remedy each of the font's insufficiencies. The most common problems are the following:
Lack of the most important font declinations as needed in scientific
documents: Bold, Italic,
Lack of specific glyphs: non English languages, mathematical symbols, and in particular big operators, extensible brackets and wide accents.
Inconsistencies: sloppy design of some glyphs that are important for
mathematics (such as  ,
,
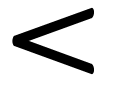 , etc.),
leading to inconsistencies.
, etc.),
leading to inconsistencies.
The main countermeasures are font substitution and font
emulation. The first technique consists of borrowing missing glyphs
from other fonts. This can either be done on the level of an entire font
(e.g. for obtaining bold or italic declinations) or for
individual characters (e.g. a missing 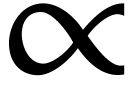 symbol, or lacking Greek characters). Font emulation consists of
combining and altering the glyphs of symbols in a font in order to
generate new ones. This can again be done for entire fonts or individual
glyphs.
symbol, or lacking Greek characters). Font emulation consists of
combining and altering the glyphs of symbols in a font in order to
generate new ones. This can again be done for entire fonts or individual
glyphs.
A prerequisite for automatic font substitutions is a detailed analysis
of the main characteristics of all supported fonts. The results of this
analysis are stored in a database. Using this database, we may then
compute the distance between two fonts. In the case when a symbol  is missing in a font
is missing in a font  ,
it then suffices to find the closest font
,
it then suffices to find the closest font  that
supports this symbol . Notice
that the best substitution font may depend on the fonts which are
installed on your system.
that
supports this symbol . Notice
that the best substitution font may depend on the fonts which are
installed on your system.
In our database we both use discrete font characteristics (e.g. sans serif, small capitals, handwritten, ancient, gothic, etc.) and continuous ones (e.g. italic slant, height of an “x” symbol, etc.). Most characteristics are determined automatically by analyzing the name of the font (for some of the discrete characteristics) or individual glyphs (for the continuous ones). Some “font categories” (such as handwritten, gothic, etc.) can be specified manually.
One of the most important font characteristics is the height of the
“x” symbol (with respect to the design size). When the font
borrows a symbol from the font
we first scale it by the quotient of these x-heights inside and .
Other common font characteristics are also taken into account into our database, such as the italic slant, the width of the “M” symbol, the ascent and descent (above and above the “x” symbol), etc. In addition, we carefully analyze the glyphs themselves in order to determine the horizontal and vertical stroke widths for the “o” and “O” symbols, the average aspect-ratios of uppercase and lowercase letters, and the average area of glyphs that is filled (how much ink will be used).
Font emulation works at the level of glyphs bitmaps, in order to produce
Bold, Italic and
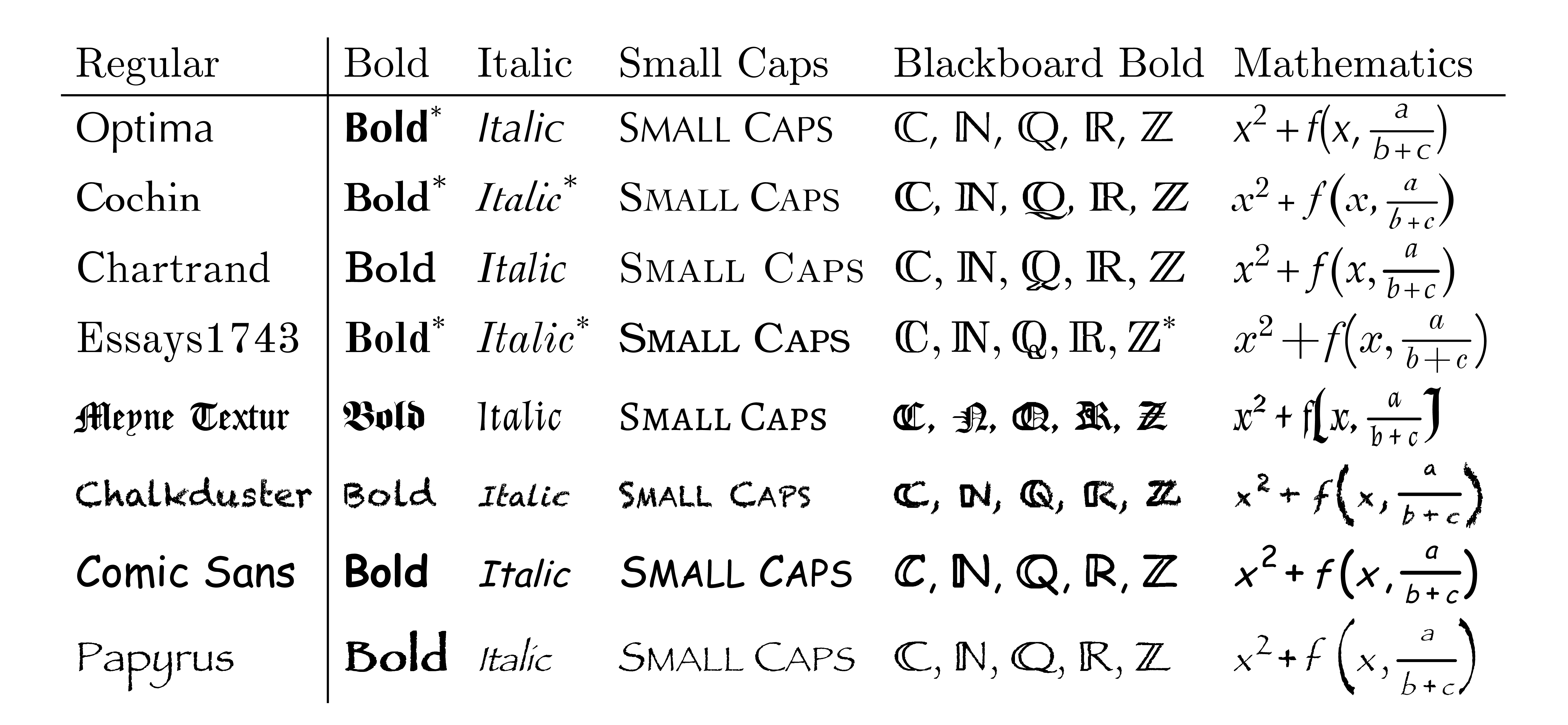 |
Missing glyphs can be generated automatically from existing ones using a combination of the following main techniques, listed by increasing complexity:
Superposition of several glyphs:  and can be combined into
and can be combined into  , and
, and  be obtained by
juxtaposing two symbols.
be obtained by
juxtaposing two symbols.
Clipping rectangular areas: cutting  and
and  in their midsts and combining them yields
in their midsts and combining them yields 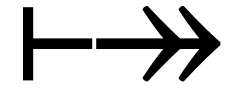 .
.
Linear transformations: combining a crushed O and an I, we may
produce the Greek capital <Phi*>. Turning around  , we obtain
, we obtain 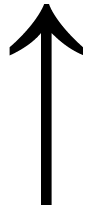 .
.
Simple graphical constructs such as circles and lines. This can for
instance be used for producing the missing half circle of  .
.
Special ad hoc transformations that directly operate on the
pixels of a glyph (or on their outlines if possible). For instance,
we designed a special “curlyfication” method that turns
into  and
and  into
into  . Similarly, we implemented a “flood
fill” algorithm for transforming
. Similarly, we implemented a “flood
fill” algorithm for transforming  into
into
 .
.
Emulation of uppercase Greek letters is obtained by gluing together pieces of certain glyphs to produce others. Lowercase Greek letters are not amenable to this approach.
One specific problem with mathematical fonts is the need for rubber
characters. There are essentially four types of them: big operators
(,  ,
,  ),
large delimiters
),
large delimiters 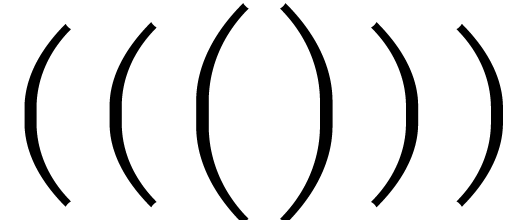
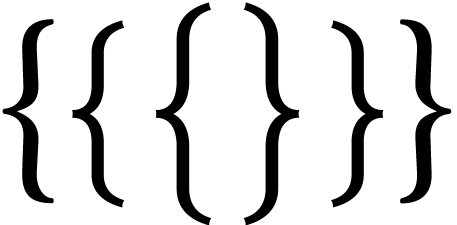 ,
wide accents (
,
wide accents ( ,
, 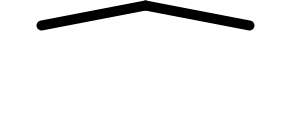 ), and long arrows (
), and long arrows ( ,
, 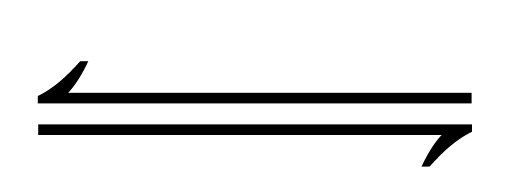 ).
).
We produce these rubber characters using essentially the same techniques as in the previous section. Especially horizontal and vertical scaling are very useful, as well as cutting symbols into several parts and reassembling them appropriately.
The main abstract font class is defined in font.hpp:
struct font_rep: rep<font> {
int type; // font type
int math_type; // For TeX Gyre math fonts and Stix
SI size; // requested size
SI design_size; // design size in points/256
SI display_size; // display size in points/PIXEL
double slope; // italic slope
space spc; // usual space between words
space extra; // extra space at end of words
space mspc; // space after mathematical operator, e.g. log x
SI sep; // separation space between close components
SI y1; // bottom y position
SI y2; // top y position
SI yx; // height of the x character
SI yfrac; // vertical position fraction bar
SI ysub_lo_base; // base line for subscripts
SI ysub_hi_lim; // upper limit for subscripts
SI ysup_lo_lim; // lower limit for supscripts
SI ysup_lo_base; // base line for supscripts
SI ysup_hi_lim; // upper limit for supscripts
SI yshift; // vertical script shift inside fractions
SI wpt; // width of one point in font
SI hpt; // height of one point in font (usually wpt)
SI wfn; // wpt * design size in points
SI wline; // width of fraction bars and so
SI wquad; // quad space (often width of widest character M)
double last_zoom; // last rendered zoom
font zoomed_fn; // zoomed font for last_zoom (or nil)
// Microtypography extensions are not shown here
font_rep (string name);
font_rep (string name, font fn);
void copy_math_pars (font fn);
virtual bool supports (string c) = 0;
virtual void get_extents (string s, metric& ex) = 0;
virtual void get_extents (string s, metric& ex, bool ligf);
virtual void get_extents (string s, metric& ex, SI xk);
virtual void get_xpositions (string s, SI* xpos);
virtual void get_xpositions (string s, SI* xpos, bool ligf);
virtual void get_xpositions (string s, SI* xpos, SI xk);
virtual void draw_fixed (renderer ren, string s, SI x, SI y) = 0;
virtual void draw_fixed (renderer ren, string s, SI x, SI y, bool ligf);
virtual void draw_fixed (renderer ren, string s, SI x, SI y, SI xk);
virtual font poor_magnify (double zoomx, double zoomy);
virtual font magnify (double zoomx, double zoomy) = 0;
virtual font magnify (double zoom);
virtual void draw (renderer ren, string s, SI x, SI y, SI xk, bool ext);
virtual void draw (renderer ren, string s, SI x, SI y);
virtual void draw (renderer ren, string s, SI x, SI y, SI xk);
// other various minor methods for glyph placements not shown
};
The main abstract routines are get_extents and draw. The first routine determines the logical and physical bounding boxes of a graphical representation of a word, the second one draws the string on the the screen.
The additional data are used for global typesetting using the font. The other virtual routines are used for determining additional properties of typeset strings.
Font selection is initiated in edit_env_rep::update_font where the variables controlling the current font, family, series, shape, size and magnification are extracted from the current environment via calls to edit_env_rep::get_string.
void
edit_env_rep::update_font () {
fn_size= (int) (((double) get_int (FONT_BASE_SIZE)) *
get_double (FONT_SIZE) + 0.5);
switch (mode) {
case 0:
case 1:
fn= smart_font (get_string (FONT), get_string (FONT_FAMILY),
get_string (FONT_SERIES), get_string (FONT_SHAPE),
get_script_size (fn_size, index_level), (int) (magn*dpi));
break;
case 2:
fn= smart_font (get_string (MATH_FONT), get_string (MATH_FONT_FAMILY),
get_string (MATH_FONT_SERIES), get_string (MATH_FONT_SHAPE),
get_string (FONT), get_string (FONT_FAMILY),
get_string (FONT_SERIES), "mathitalic",
get_script_size (fn_size, index_level), (int) (magn*dpi));
break;
case 3:
fn= smart_font (get_string (PROG_FONT), get_string (PROG_FONT_FAMILY),
get_string (PROG_FONT_SERIES), get_string (PROG_FONT_SHAPE),
get_string (FONT), get_string (FONT_FAMILY) * "-tt",
get_string (FONT_SERIES), get_string (FONT_SHAPE),
get_script_size (fn_size, index_level), (int) (magn*dpi));
break;
}
string eff= get_string (FONT_EFFECTS);
if (N(eff) != 0) fn= apply_effects (fn, eff);
}
Selection proceed according to the current mode 0, 1, 2 or 3. See edit_env_rep::update_mode for the conversion between the environment variable "mode" and the variables edit_env_rep::mode and edit_env_rep::modeop. Different versions of the function smart_font() are called: either
font smart_font (string family, string variant, string series, string shape,
int sz, int dpi);
or (for "math" and "prog" modes)
font smart_font (string family, string variant, string series, string shape,
string tfam, string tvar, string tser, string tsh,
int sz, int dpi);
The second version make some adjustment and call the first version. The function reads
font
smart_font (string family, string variant, string series, string shape,
string tfam, string tvar, string tser, string tsh,
int sz, int dpi) {
if (!new_fonts) return find_font (family, variant, series, shape, sz, dpi);
if (tfam == "roman") tfam= family;
if (variant != "mr") {
if (variant == "ms") tvar= "ss";
if (variant == "mt") tvar= "tt";
}
if (shape == "right") tsh= "mathupright";
return smart_font (tfam, tvar, tser, tsh, sz, dpi);
}
as we see, in the new font mechanism (selected via the new_fonts global boolean), we ignore the mode-dependent font selection variables, in favour of the main font variables, but we make local adjustment to carry over correctly the variant and shape selection.
A smart font collects and coordinates various physical fonts in order to represent the full spectrum of TeXmacs basic entities (TeXmacs universal encoding) and handles also various customizations and effects. The structure has various fields:
struct smart_font_rep: font_rep {
string mfam;
string family;
string variant;
string series;
string shape;
string rshape;
int sz;
int hdpi;
int dpi;
int math_kind;
int italic_nr;
array<font> fn;
smart_map sm;
smart_font_rep (string name, font base_fn, font err_fn,
string family, string variant,
string series, string shape, int sz, int hdpi, int vdpi);
// […] methods are not shown here
}
The value of the family field can be quite complex for smart fonts. A typical font can be instantiated in a TeXmacs document with an assignment to the font environment variable as such:
<assign|font|mathlarge=TeX Gyre Pagella,cal=TeX Gyre Termes,bold-cal=TeX Gyre Termes,frak=TeX Gyre Pagella,Fira>
It is a string with comma separated fields and a final value which determines the main family mfam while the others determine special subfonts for certain groups of entities.
A key field which controls the behaviour of the smart font is math_kind. The possible values are 0,1,2,3 and it is set in the constructor of the structure according to the value of the shape parameter. The value 0 is the default. If shape is one of "mathitalic", "mathupright", "mathshape" then math_kind is, respectively, set to 1,2,3. This is used to determine the shape of alphabetic and Greek characters according to different conventions [to be completed].
To understand how smart fonts work we can look at one of the entrypoints of the font mechanics, the draw_fixed method, which renders an entity on a graphical device.
void
smart_font_rep::draw_fixed (renderer ren, string s, SI x, SI y) {
int i=0, n= N(s);
while (i < n) {
int nr;
string r= s;
metric ey;
advance (s, i, r, nr);
if (nr >= 0) {
fn[nr]->draw_fixed (ren, r, x, y);
if (i < n) {
fn[nr]->get_extents (r, ey);
x += ey->x2;
}
}
}
}
In this case it off-loads the real work to a particular subfont fn[nr] which is determined by a call to the dispatching function smart_font_rep::advance whose result is to obtain a subfont number nr and, possibly a different representation of the entity in the string r. A value -1 for nr is considered an invalid font and ignored.
The advance method, scans the input string at the given position and looks up the entities using either caching mechanism provided by smart_map:
struct smart_map_rep: rep<smart_map> {
int chv[256];
hashmap<string,int> cht;
hashmap<tree,int> fn_nr;
array<tree> fn_spec;
array<int> fn_rewr;
public:
smart_map_rep (string name, tree fn);
int add_font (tree fn, int rewr);
int add_char (tree fn, string c);
};
where chv give a subfont number for single byte characters while cht provide subfont lookup for other entities. If this lookup returns the invalid subfont -1 then we proceed to determine the appropriate subfont via the resolve method. Once we got a subfont we may initialize it if needed, and the proceed to some rewriting, controlled by the value of smartmap's fn_rewr[nr] field, according to the values
#define REWRITE_NONE 0 #define REWRITE_MATH 1 #define REWRITE_CYRILLIC 2 #define REWRITE_LETTERS 3 #define REWRITE_SPECIAL 4 #define REWRITE_EMULATE 5 #define REWRITE_POOR_BBB 6 #define REWRITE_ITALIC_GREEK 7 #define REWRITE_UPRIGHT_GREEK 8 #define REWRITE_UPRIGHT 9 #define REWRITE_ITALIC 10 #define REWRITE_IGNORE 11
For example, in case fn_rewr[nr] == REWRITE_MATH we perform a rewriting according to the function
static string
rewrite_math (string s) {
string r;
int i= 0, n= N(s);
while (i < n) {
int start= i;
tm_char_forwards (s, i);
if (s[start] == '<' && start+1 < n && s[start+1] == '#' && s[i-1] == '>')
r << utf8_to_cork (strict_cork_to_utf8 (s (start, i)));
else r << s (start, i);
}
return r;
}
Each entity is transformed back and forth from Cork to UTF8, which has as effect to transform some entities in unicode points which are represented in TeXmacs' encoding as <#xxxx>.
Let's make a brief digression on how this is implemented before continuing. utf8_to_cork is implemented in converter.cpp and uses a converter object instantiated via
converter conv= load_converter ("UTF-8", "Cork");
and similarly for strict_cork_to_utf8. The relevant code which construct the conversion tables is in converter_rep::load and reads:
else if (from=="UTF-8" && to=="Cork") {
hashtree<char,string> dic;
hashtree_from_dictionary (dic,"corktounicode", UTF8, BIT2BIT, true);
hashtree_from_dictionary (dic,"unicode-cork-oneway", UTF8, BIT2BIT, false);
hashtree_from_dictionary (dic,"tmuniversaltounicode", UTF8, BIT2BIT, true);
hashtree_from_dictionary (dic,"unicode-symbol-oneway", UTF8, BIT2BIT, true);
ht = dic;
}
if (from=="Strict-Cork" && to=="UTF-8" ) {
hashtree<char,string> dic;
hashtree_from_dictionary (dic,"corktounicode", BIT2BIT, UTF8, false);
hashtree_from_dictionary (dic,"cork-unicode-oneway", BIT2BIT, UTF8, false);
hashtree_from_dictionary (dic,"tmuniversaltounicode", BIT2BIT, UTF8, false);
hashtree_from_dictionary (dic,"symbol-unicode-oneway", BIT2BIT, UTF8, false);
hashtree_from_dictionary (dic,"symbol-unicode-math", BIT2BIT, UTF8, false);
ht = dic;
}
the boolean value determine if we construct the direct (false) or inverse (true) mapping. The various tables are encoded in Scheme expressions in various files in $TEXMACS_PATH/langs/encoding.
We go back now to entity resolution in smart_font. The next step is how resolve works. The function is overloaded. The basic form is
int smart_font_rep::resolve (string c)
which performs some basic dispatching for entities.
If math_kind != 0 we perform the following resolutions:
Entities <up-XXX> are associated to a REWRITE_UPRIGHT rewrite rule, provided the fn[SUBFONT_MAIN] font supports the basic character, or entity.
Entities <up-XXX> for greek letters are associated to a REWRITE_UPRIGHT_GREEK rewrite rule, provided the fn[SUBFONT_MAIN] font supports it.
Same for italic greek letters.
Several specific entities are associated to the "italic-math" subfont (e.g. <imath>, <jmath>, <ell>).
Special entities (as determined by is_special, provided some side conditions are not met) are associated to the "special" subfont which is the shape="right" variant of the smart font. They corresponds to various mathematical entities including those in the form <big-XXXX-N> which represent large glyphs or operators.
Other entities are associated to the "emu-bracket" subfont, if appropriate. See find_in_emu_bracket.
If these cases do not apply we continue. If the shape is mathupright and we are looking at the standard roman family, we lookup the non-alphabetic characters in the standard mathitalic font with a specific subfont with label "italic-roman":
if (mfam == "roman" && shape == "mathupright" &&
(variant == "rm" || variant == "ss" || variant == "tt") &&
N(c) == 1 && (c[0] < 'A' || c[0] > 'Z') && (c[0] < 'a' || c[0] > 'z'))
return sm->add_char (tuple ("italic-roman"), c);
At this point we need to take into account the structure of the font family string. Keep in mind that it might looks like this:
"mathlarge=TeX Gyre Pagella,cal=TeX Gyre Termes,bold-cal=TeX Gyre Termes," "frak=TeX Gyre Pagella,Fira"
This particular syntax is called a font sequence. We split the various subfields with something like:
array<string> a= trimmed_tokenize (family, ",");
We call each element a subfont selector. The main font (family) is the first comma separated field which is not a substring containing an "=" character, can be extracted via the main_family function and call it the main selector. The other selectors are assumed to be pairs of the form "XXX=YYY", where the l.h.s. determines a particular subrange of entities and the r.h.s. the font to be used for their rendering.
For each selector in the a array, we perform a resolution with
int smart_font_rep::resolve (string c, string fam, int attempt)
here the attempt variable indicate the number of attempts we already performed. This function implements the semantics of the font sequence string, allowing to choose different fonts for subranges of glyphs, or variants (like bold, italic, etc…).
For selectors fam of the form "selector field=selector font" it checks that the selector field matches either the glyph c or the indicated selector font's characteristics. Selector fields can be of the following types:
a particular feature, as returned by the logical_font function applied to the font's characteristics (family, variant, series and rshape);
an unicode range: one of latin, greek, cyrillic, cjk, hiragana, hangul, mathsymbols, mathextra, mathletters, mathlarge, mathbigops, mathrubber (see in_unicode_range for details);
a mathematical alphabet range, i.e. one of bold-math, italic-math, bold-italic-math, cal, bold-cal, frak, bold-frak, bbb, ss, bold-ss, italic-ss, bold-italic-ss, tt (see the substitute_math_letter function);
a particular entity (e.g. <alpha> or <ell>);
a letter range: digit, latin, latin-bold, greek, basic-letters, uppercase-latin, uppercase-latin-bold, lowercase-latin, lowercase-latin-bold, greek-bold, uppercase-greek, uppercase-greek-bold, lowecase-greek, lowecase-greek-bold, (see the in_collection function);
the "!" character followed by a letter range, to exclude a particular range;
a selector in the form "XXXX:YYYY" where XXXX and YYYY are TeXmacs entities, to match an unicode range.
In case it does, and we are at the first attempt, it proceed to allocate the glyph to the given font following several heuristics. In particular, if the font is the main font (this happens for the last font sequence element) we check if fn[SUBFONT_MAIN] can render the entity, otherwise if the font is not the main font, we need to first look up the font and check if we can render the entity. If all this does not work we have to do otherwise and look elsewhere for the glyph before failing. In particular we have special cases for TeX and similar fonts which have a complex resolution of entities for mathematical typesetting and we need to instantiate an appropriate math_font to handle them. This case is determined by the function is_math_family. Cyrillic and Greek letters have also special handling in case the font is roman. We implement here also the fallback for blackboard bold entities <bbb-X> with synthetic subfonts with label "poor-bbb". If the entity is an italic letter <it-X>, we dispatch it to the "it" subfont with a REWRITE_ITALIC semantics. Finally, for the main selector, we check the emulated fonts as returned by the emu_font_names function, in case we find an appropriate match we instantiate a glyph in an "emulate" subfont.
If this first attempt fails the function returns the invalid subfont selector -1. We check now if the entity is rubber. Rubbers are entities like <large-sqrt-2> or <left-lparen-4> which are extensible either horizontally or vertically. Whether an entity is rubber or not is determined by
static bool
is_rubber (string c) {
return (starts (c, "<large-") ||
starts (c, "<left-") ||
starts (c, "<right-") ||
starts (c, "<mid-")) && ends (c, ">");
}
Note that some rubber entities can be matched in the earlier attempts, e.g. by mathlarge, mathbigops or mathrubber selectors, and supported by a physical font, e.g. by an unicode_fonts below in Section 8.2. Generally however fonts only support the base size of a rubber glyph, e.g. in $TEXMACS_PATH/langs/encoding/symbol-unicode-oneway.scm we have (among other translations)
("<large-less-0>" "<")
("<large-gtr-0>" ">")
("<large-(>" "(")
("<large-)>" ")")
("<large-(-0>" "(")
("<large-)-0>" ")")
("<large-[>" "[")
("<large-]>" "]")
("<large-[-0>" "[")
("<large-]-0>" "]")
("<large-lceil>" "#2308")
("<large-rceil>" "#2309")
("<large-lfloor>" "#230A")
("<large-rfloor>" "#230B")
("<large-lceil-0>" "#2308")
("<large-rceil-0>" "#2309")
("<large-lfloor-0>" "#230A")
("<large-rfloor-0>" "#230B")
For the other sizes we need larger or stretched variants of those glyphs. This is the job of the rubber fonts, therefore for rubber entities which arrive at this point we try to instantiate a substitute in the "rubber" subfont which tries to render the glyph via the best method, and ultimately synthetizes it via some virtual font, see Section 8.1.
If the entity is not rubber, the resolution process then restart by scanning again all the selectors with an higher attempt number. At this point, since attempt>1 the resolution however proceed differently. If the entity belongs to some mathematical alphabet as detected via substitute_math_letter, then we stop further attempts and we dispatch the glyph to one of the subfonts for variants of alphabetical glyphs associated with one of the keys:
"bold-math", "italic-math", "bold-italic-math", "cal", "bold-cal", "frak", "bold-frak", "bbb", "ss", "bold-ss", "italic-ss", "bold-italic-ss", "tt".
If the entity is not a mathematical letter, we need attempt to find a suitable replacement font via the use TeXmacs mechanism for searching fonts with similar characteristics. This is implemented via the function
font closest_font (string family, string variant, string series, string shape,
int sz, int dpi, int attempt)
to find an appropriate substitute. We indicate the required entity by augmenting the variant field with the unicode range of the required glyph, as returned by the get_unicode_range function:
string
get_unicode_range (int code) {
if (code <= 0x7f) return "ascii";
else if (code >= 0x80 && code <= 0x37f) return "latin";
else if (code >= 0x380 && code <= 0x3ff) return "greek";
else if (code >= 0x400 && code <= 0x4ff) return "cyrillic";
else if (code >= 0x3000 && code <= 0x303f) return "cjk";
else if (code >= 0x4e00 && code <= 0x9fcc) return "cjk";
else if (code >= 0xff00 && code <= 0xffef) return "cjk";
else if (code >= 0x3040 && code <= 0x309F) return "hiragana";
else if (code >= 0xac00 && code <= 0xd7af) return "hangul";
else if (code >= 0x2000 && code <= 0x23ff) return "mathsymbols";
else if (code >= 0x2900 && code <= 0x2e7f) return "mathextra";
else if (code >= 0x1d400 && code <= 0x1d7ff) return "mathletters";
else return "";
}
In case we manage to find a suitable font we instantiate it as a subfont with a key of the form
tree key= tuple (fam, augmented_variant, series, rshape, as_string (attempt-1));
After a number of attempts determined by FONT_ATTEMPTS we give up. At this point we try virtual fonts via find_in_virtual and if successful instantiate the virtual font with key "virtual".
Other special cases are dispatched to the "other" subfont. Finally we assign the glyph to the "error" subfont and show it as a red string. This concludes the description of the resolution mechanics.
The semantics of the subfont keys is determined at the moment we instantiated the subfonts in initialize_font, as follows. The fn_spec[nr] field of smart_map is a tree which specify the kind of font
void
smart_font_rep::initialize_font (int nr) {
if (N(fn) <= nr) fn->resize (nr+1);
if (!is_nil (fn[nr])) return;
array<string> a= tuple_as_array (sm->fn_spec[nr]);
if (a[0] == "math")
fn[nr]= adjust_subfont (get_math_font (a[1], a[2], a[3], a[4]));
else if (a[0] == "cyrillic")
fn[nr]= adjust_subfont (get_cyrillic_font (a[1], a[2], a[3], a[4]));
else if (a[0] == "greek")
fn[nr]= adjust_subfont (get_greek_font (a[1], a[2], a[3], a[4]));
else if (a[0] == "subfont")
fn[nr]= smart_font_bis (a[1], variant, series, shape, sz, hdpi, dpi);
else if (a[0] == "special")
fn[nr]= smart_font_bis (family, variant, series, "right", sz, hdpi, dpi);
else if (a[0] == "emu-bracket")
fn[nr]= virtual_font (this, "emu-bracket", sz, hdpi, dpi, false);
else if (a[0] == "other") {
int nvdpi= adjusted_dpi ("roman", variant, series, "mathitalic", 1);
int nhdpi= (hdpi * nvdpi + (dpi>>1)) / dpi;
fn[nr]= smart_font_bis ("roman", variant, series, "mathitalic", sz,
nhdpi, nvdpi);
}
else if (a[0] == "bold-math")
fn[nr]= smart_font_bis (family, variant, "bold", "right", sz, hdpi, dpi);
else if (a[0] == "fast-italic")
fn[nr]= smart_font_bis (family, variant, series, "italic", sz, hdpi, dpi);
else if (a[0] == "italic-math")
fn[nr]= smart_font_bis (family, variant, series, "italic", sz, hdpi, dpi);
else if (a[0] == "italic-roman")
fn[nr]= smart_font_bis (family, variant, series, "mathitalic", sz,
hdpi, dpi);
else if (a[0] == "bold-italic-math")
fn[nr]= smart_font_bis (family, variant, "bold", "italic", sz, hdpi, dpi);
else if (a[0] == "italic-greek")
fn[nr]= fn[SUBFONT_MAIN];
else if (a[0] == "upright-greek")
fn[nr]= fn[SUBFONT_MAIN];
else if (a[0] == "up")
fn[nr]= fn[SUBFONT_MAIN];
else if (a[0] == "it")
fn[nr]= smart_font_bis (family, variant, series, "italic", sz, hdpi, dpi);
else if (a[0] == "tt")
fn[nr]= smart_font_bis (family, "tt", series, "right", sz, hdpi, dpi);
else if (a[0] == "ss")
fn[nr]= smart_font_bis (family, "ss", series, "right", sz, hdpi, dpi);
else if (a[0] == "bold-ss")
fn[nr]= smart_font_bis (family, "ss", "bold", "right", sz, hdpi, dpi);
else if (a[0] == "italic-ss")
fn[nr]= smart_font_bis (family, "ss", series, "italic", sz, hdpi, dpi);
else if (a[0] == "bold-italic-ss")
fn[nr]= smart_font_bis (family, "ss", "bold", "italic", sz, hdpi, dpi);
else if (a[0] == "cal" && N(a) == 1)
fn[nr]= smart_font_bis (family, "calligraphic", series, "italic", sz,
hdpi, dpi);
else if (a[0] == "bold-cal")
fn[nr]= smart_font_bis (family, "calligraphic", "bold", "italic", sz,
hdpi, dpi);
else if (a[0] == "frak")
fn[nr]= smart_font_bis (family, "gothic", series, "right", sz, hdpi, dpi);
else if (a[0] == "bold-frak")
fn[nr]= smart_font_bis (family, "gothic", "bold", "right", sz, hdpi, dpi);
else if (a[0] == "bbb" && N(a) == 1)
fn[nr]= smart_font_bis (family, "outline", series, "right", sz, hdpi, dpi);
else if (a[0] == "virtual")
fn[nr]= virtual_font (this, a[1], sz, hdpi, dpi, false);
else if (a[0] == "emulate") {
font vfn= fn[SUBFONT_MAIN];
if (a[1] != "emu-fundamental")
vfn= virtual_font (vfn, "emu-fundamental", sz, hdpi, dpi, true);
fn[nr]= virtual_font (vfn, a[1], sz, hdpi, dpi, true);
}
else if (a[0] == "poor-bold" && N(a) == 1) {
font sfn= smart_font_bis (family, variant, "medium", shape, sz, hdpi, dpi);
double emb= 5.0/3.0;
double fat= ((emb - 1.0) * sfn->wline) / sfn->wfn;
fn[nr]= poor_bold_font (sfn, fat, fat); }
else if (a[0] == "poor-bbb" && N(a) == 3) {
double pw= as_double (a[1]);
double ph= as_double (a[2]);
font sfn= smart_font_bis (family, variant, series, "right", sz, hdpi, dpi);
fn[nr]= poor_bbb_font (sfn, pw, ph, 1.5*pw); }
else if (a[0] == "rubber" && N(a) == 2 && is_int (a[1])) {
initialize_font (as_int (a[1]));
fn[nr]= adjust_subfont (rubber_font (fn[as_int (a[1])]));
//fn[nr]= adjust_subfont (rubber_unicode_font (fn[as_int (a[1])]));
}
else if (a[0] == "ignore")
fn[nr]= fn[SUBFONT_MAIN];
else {
int ndpi= adjusted_dpi (a[0], a[1], a[2], a[3], as_int (a[4]));
font cfn = closest_font (a[0], a[1], a[2], a[3], sz, ndpi, as_int (a[4]));
fn[nr]= adjust_subfont (cfn);
}
//cout << "Font " << nr << ", " << a << " -> " << fn[nr]->res_name << "\n";
if (fn[nr]->res_name == res_name) {
failed_error << "Font " << nr << ", " << a
<< " -> " << fn[nr]->res_name << "\n";
FAILED ("substitution font loop detected");
}
}
Rubber fonts take care of large variants of delimiters like brackets and square roots, described by entities like <large-lceil-X> where X=0,1,2,3,.. is some small integer. The interface is the function
font rubber_font (font base);
which returns a font appropriate to render the rubber for a base font base. It caches the result of a call to
static font
make_rubber_font (font fn) {
string name= locase_all (fn->res_name);
if (starts (name, "stix-") ||
starts (name, "stix,") ||
occurs (",stix,", name) ||
occurs ("math=stix", name) ||
occurs ("mathrubber=stix", name))
return rubber_stix_font (fn);
else if (occurs ("mathlarge=", name) ||
occurs ("mathrubber=", name))
return fn;
else if (has_poor_rubber && fn->type == FONT_TYPE_UNICODE)
return poor_rubber_font (fn);
else if (fn->type == FONT_TYPE_UNICODE)
return rubber_unicode_font (fn);
else
return fn;
}
There is some special handling for STIX fonts which we ignore for the moment, moreover if the family name contain a specific selector for mathlarge or mathrubber, then we instantiate the same font, inhibiting any emulation of rubber before the proper handling of the selector (as we have seen in smart_font_rep::resolve). In case the base font is an unicode font, the global bool flag has_poor_rubber (which by default is true) controls whether we try to synthesize rubber or we use the font's provided one. If everything else is not appropriate we return the base font.
A poor_rubber font has the duty of rendering TeXmacs entities which come in various sizes according to some hard-coded heuristics.
struct poor_rubber_font_rep: font_rep {
font base;
bool big_flag;
array<bool> initialized;
array<font> larger;
translator virt;
poor_rubber_font_rep (string name, font base);
font get_font (int nr);
int search_font (string s, string& r);
// + virtual methods from the base class
};
It relies on magnified versions of the fonts stored in the larger field and on virtual fonts to synthesize even larger versions of some of the glyphs via the "emu-large" virtual font (see Section 8.4).
#define MAGNIFIED_NUMBER 4
#define HUGE_ADJUST 1
poor_rubber_font_rep::poor_rubber_font_rep (string name, font base2):
font_rep (name, base2), base (base2),
big_flag (supports_big_operators (base2->res_name))
{
this->copy_math_pars (base);
initialized << true;
larger << base;
for (int i=1; i<=2*MAGNIFIED_NUMBER+5; i++) {
initialized << false;
larger << base;
}
virt= load_translator ("emu-large");
}
The boolean field big_flag is true according to the result of supports_big_operators:
bool
supports_big_operators (string res_name) {
if (occurs (" Math", res_name))
return occurs ("TeX Gyre ", res_name);
if (occurs ("mathitalic", res_name))
return occurs ("bonum", res_name) ||
occurs ("pagella", res_name) ||
occurs ("schola", res_name) ||
occurs ("termes", res_name);
return false;
}
It indicates whether the font is capable of rendering bigger version of
standard operators like sums, products, direct sums, etc... (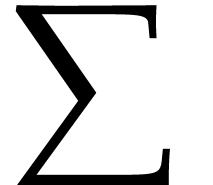 ,
,  ,
⊕, ...). Essentially only math fonts are capable of that and in
the current version of TeXmacs only the math features for TeX Gyre fonts
are implemented.
,
⊕, ...). Essentially only math fonts are capable of that and in
the current version of TeXmacs only the math features for TeX Gyre fonts
are implemented.
The field larger is an array of 2*MAGNIFIED_NUMBER+5 fonts. The meaning of each slot is determined by the search_font function, which tries to locate the appropriate subfont (as return value) for a given TeXmacs entity s, eventually mapping it to another entity r.
int
poor_rubber_font_rep::search_font (string s, string& r) {
if (starts (s, "<big-") && (ends (s, "-1>") || ends (s, "-2>"))) {
r= s;
if (starts (s, "<big-iint") || starts (s, "<big-iiint") ||
starts (s, "<big-iiiint") || starts (s, "<big-oint") ||
starts (s, "<big-oiint") || starts (s, "<big-oiiint") ||
starts (s, "<big-upiint") || starts (s, "<big-upiiint") ||
starts (s, "<big-upiiiint") || starts (s, "<big-upoint") ||
starts (s, "<big-upoiint") || starts (s, "<big-upoiiint") ||
starts (s, "<big-amalg") || starts (s, "<big-pluscup"))
if (!big_flag) return 2*MAGNIFIED_NUMBER + 5;
if (starts (s, "<big-idotsint") || starts (s, "<big-upidotsint") ||
starts (s, "<big-triangleup") || starts (s, "<big-box") ||
starts (s, "<big-parallel") || starts (s, "<big-interleave"))
return 2*MAGNIFIED_NUMBER + 5;
if (big_flag && ends (s, "-1>") && base->supports (s)) return 0;
return 2*MAGNIFIED_NUMBER + 4;
}
if (starts (s, "<mid-")) s= "<left-" * s (5, N(s));
if (starts (s, "<right-")) s= "<left-" * s (7, N(s));
if (starts (s, "<large-")) s= "<left-" * s (7, N(s));
if (starts (s, "<left-")) {
int pos= search_backwards ("-", N(s), s), num;
if (pos > 6) { r= s (6, pos); num= as_int (s (pos+1, N(s)-1)); }
else { r= s (6, N(s)-1); num= 0; }
//cout << "Search " << base->res_name << ", " << s
// << ", " << r << ", " << num << LF;
int nr= max (num - 5, 0);
int thin= (is_thin (r)? 1: 0);
int code;
if (num <= MAGNIFIED_NUMBER ||
r == "/" || r == "\\" ||
r == "langle" || r == "rangle" ||
r == "llangle" || r == "rrangle") {
num= min (num, MAGNIFIED_NUMBER);
if (N(r) > 1) r= "<" * r * ">";
if (N(r)>1 && !base->supports (r)) {
if (r == "<||>") r= "<emu-dbar>";
else if (r == "<interleave>") r= "<emu-tbar>";
else if (r == "<llbracket>") r= "<emu-dlbracket>";
else if (r == "<rrbracket>") r= "<emu-drbracket>";
else r= "<emu-" * r (1, N(r)-1) * ">";
}
else if (r == "\\" && base->supports ("/")) {
metric ex1, ex2;
base -> get_extents ("/", ex1);
base -> get_extents ("\\", ex2);
double h1= ex1->y2 - ex1->y1;
double h2= ex2->y2 - ex2->y1;
if (fabs ((h2/h1) - 1.0) > 0.05) r= "<emu-backslash>";
}
return 2*num + thin;
}
else if (r == "(")
code= virt->dict ["<rubber-lparenthesis-#>"];
else if (r == ")")
code= virt->dict ["<rubber-rparenthesis-#>"];
else if (r == "[")
code= virt->dict ["<rubber-lbracket-#>"];
else if (r == "]")
code= virt->dict ["<rubber-rbracket-#>"];
else if (r == "{")
code= virt->dict ["<rubber-lcurly-#>"];
else if (r == "}")
code= virt->dict ["<rubber-rcurly-#>"];
else if (r == "|")
code= virt->dict ["<rubber-bar-#>"];
else if (r == "||") {
if (base->supports ("<||>"))
code= virt->dict ["<rubber-parallel-#>"];
else code= virt->dict ["<rubber-parallel*-#>"];
}
else if (r == "interleave") {
if (base->supports ("<interleave>"))
code= virt->dict ["<rubber-interleave-#>"];
else code= virt->dict ["<rubber-interleave*-#>"];
}
else if (r == "lfloor" || r == "rfloor" ||
r == "lceil" || r == "rceil" ||
r == "llbracket" || r == "rrbracket") {
if (base->supports ("<" * r * ">"))
code= virt->dict ["<rubber-" * r * "-#>"];
else code= virt->dict ["<rubber-" * r * "*-#>"];
}
else if (r == "dlfloor" || r == "drfloor" ||
r == "dlceil" || r == "drceil" ||
r == "tlbracket" || r == "trbracket" ||
r == "tlfloor" || r == "trfloor" ||
r == "tlceil" || r == "trceil")
code= virt->dict ["<rubber-" * r * "-#>"];
else if (r == "sqrt") {
code= virt->dict ["<rubber-sqrt-#>"];
r= string ((char) code) * as_string (nr + HUGE_ADJUST) * ">";
return 2*MAGNIFIED_NUMBER + 5;
}
else
code= virt->dict ["<rubber-lparenthesis-#>"];
r= string ((char) code) * as_string (nr + HUGE_ADJUST) * ">";
return 2*MAGNIFIED_NUMBER + 2 + thin;
}
r= s;
return 0;
}
The coding of this function is relatively straightforward.
For entities of the form <big-XXXX-N> with N=1,2 we use the subfont of index 2*MAGNIFIED_NUMBER + 5 is used if big_flag is false or in case big_flag is true, for the big variants with N=2 while for those at N=1 the base font is used. The subfont at index 2*MAGNIFIED_NUMBER + 4 is used in this case for the N=2 sized glyphs.
Otherwise we normalize all entities of the form <left-XXXX-N>, <mid-XXXX-N>, <right-XXXX-N>, into <large-XXXX-N> and extract the value of N. For small values of N we use the subfont at index 2*N+thin where thin=0,1 according to the return value of the is_thin function:
static hashset<string> thin_delims;
static bool
is_thin (string s) {
if (N(thin_delims) == 0)
thin_delims << string ("|") << string ("||") << string ("interleave")
<< string ("[") << string ("]")
<< string ("lfloor") << string ("rfloor")
<< string ("lceil") << string ("rceil")
<< string ("llbracket") << string ("rrbracket")
<< string ("dlfloor") << string ("drfloor")
<< string ("dlceil") << string ("drceil")
<< string ("tlbracket") << string ("trbracket")
<< string ("tlfloor") << string ("trfloor")
<< string ("tlceil") << string ("trceil");
return thin_delims->contains (s);
}
For larger glyphs we fallback to the appropriate parametrized glyph in the virtual font encoding the value of the size parameter in the rewriting entity r (see the virtual font for how this precisely works).
The physical font associated to each subfont index is determined by the get_font method:
font
poor_rubber_font_rep::get_font (int nr) {
ASSERT (nr < N(larger), "wrong font number");
if (initialized[nr]) return larger[nr];
initialized[nr]= true;
if (nr <= 2*MAGNIFIED_NUMBER + 1) {
int hnr= nr / 2;
double zoomy= pow (2.0, ((double) hnr) / 4.0);
double zoomx= sqrt (zoomy);
if ((nr & 1) == 1) zoomx= sqrt (zoomx);
larger[nr]= poor_stretched_font (base, zoomx, zoomy);
//larger[nr]= base->magnify (zoomx, zoomy);
}
else if (nr == 2*MAGNIFIED_NUMBER + 2 || nr == 2*MAGNIFIED_NUMBER + 3) {
int hdpi= (72 * base->wpt + (PIXEL/2)) / PIXEL;
int vdpi= (72 * base->hpt + (PIXEL/2)) / PIXEL;
font vfn= virtual_font (base, "emu-large", base->size, hdpi, vdpi, false);
double zoomy= pow (2.0, ((double) MAGNIFIED_NUMBER) / 4.0);
double zoomx= sqrt (zoomy);
if ((nr & 1) == 1) zoomx= sqrt (zoomx);
larger[nr]= poor_stretched_font (vfn, zoomx, zoomy);
//larger[nr]= vfn->magnify (zoomx, zoomy);
}
else if (nr == 2*MAGNIFIED_NUMBER + 5) {
int hdpi= (72 * this->wpt + (PIXEL/2)) / PIXEL;
int vdpi= (72 * this->hpt + (PIXEL/2)) / PIXEL;
font vfn= virtual_font (this, "emu-large", this->size, hdpi, vdpi, false);
larger[nr]= vfn;
}
else
larger[nr]= rubber_unicode_font (base);
return larger[nr];
}
which dispatches as follows:
it associates magnified versions of the font to all indexed from 0 to 2*MAGNIFIED_NUMBER + 1 with the index of the form 2*n+0 horizontally zoomed via the square root of the vertical zoom and those with index 2*n+1, zoomed horizontally with the fourth root of the vertical zoom to make them more elongated;
the index 2*MAGNIFIED_NUMBER + 2 and 2*MAGNIFIED_NUMBER + 3 are associated to normal and thin versions of magnified "emu-large" virtual glyphs;
while 2*MAGNIFIED_NUMBER + 5 to normal versions of the virtual font;
and finally 2*MAGNIFIED_NUMBER + 4 to the rubber_unicode_font based on the same font as this rubber font.
Unicode fonts are capable of indexing unicode glyphs in physical fonts (i.e. modern TrueType, or OpenType font files which can handle the whole unicode space without special encodings)
struct unicode_font_rep: font_rep {
string family;
int hdpi;
int vdpi;
font_metric fnm;
font_glyphs fng;
int ligs;
hashmap<string,int> native; // additional native (non unicode) characters
unicode_font_rep (string name, string family, int size, int hdpi, int vdpi);
void tex_gyre_operators ();
unsigned int read_unicode_char (string s, int& i);
unsigned int ligature_replace (unsigned int c, string s, int& i);
// + virtual functions from the base class
};
The constructors set the font_rep::type field to FONT_TYPE_UNICODE, load the metric and glyph informations from the font file which is (ultimately) retrieved via the function
tt_face load_tt_face (string name);
and initializes the various metric information with values from the physical font and suitable heuristics for the mathematical measurements:
// in unicode_font_rep::unicode_font_rep (…)
// get main font parameters
metric ex;
get_extents ("f", ex);
y1= ex->y1;
y2= ex->y2;
get_extents ("p", ex);
y1= min (y1, ex->y1);
y2= max (y2, ex->y2);
get_extents ("d", ex);
y1= min (y1, ex->y1);
y2= max (y2, ex->y2);
display_size = y2-y1;
design_size = size << 8;
// get character dimensions
get_extents ("x", ex);
yx = ex->y2;
get_extents ("M", ex);
wquad = ex->x2;
// compute other heights
yfrac = yx >> 1;
ysub_lo_base = -yx/3;
ysub_hi_lim = (5*yx)/6;
ysup_lo_lim = yx/2;
ysup_lo_base = (5*yx)/6;
ysup_hi_lim = yx;
yshift = yx/6;
// compute other widths
wpt = (hdpi*PIXEL)/72;
hpt = (vdpi*PIXEL)/72;
wfn = (wpt*design_size) >> 8;
wline = wfn/20;
// get fraction bar parameters; reasonable compromise between several fonts
if (supports ("<#2212>")) get_extents ("<#2212>", ex);
else if (supports ("+")) get_extents ("+", ex);
else if (supports ("-")) get_extents ("-", ex);
else get_extents ("x", ex);
yfrac= (ex->y1 + ex->y2) >> 1;
if (supports ("<#2212>") || supports ("+") || supports ("-")) {
wline= ex->y2 - ex->y1;
if (supports ("<#2212>"));
else if (supports ("<#2013>")) {
get_extents ("<#2013>", ex);
wline= min (wline, ex->y2 - ex->y1);
}
wline= max (min (wline, wfn/8), wfn/48);
if (!supports ("<#2212>")) yfrac += wline/4;
}
if (starts (res_name, "unicode:Papyrus.")) wline= (2*wline)/3;
// get space length
get_extents (" ", ex);
spc = space ((3*(ex->x2-ex->x1))>>2, ex->x2-ex->x1, (3*(ex->x2-ex->x1))>>1);
extra= spc/2;
mspc = spc;
sep = wfn/10;
// get_italic space
get_extents ("f", ex);
SI italic_spc= (ex->x4-ex->x3)-(ex->x2-ex->x1);
slope= ((double) italic_spc) / ((double) display_size) - 0.05;
if (slope<0.15) slope= 0.0;
// determine whether we are dealing with a monospaced font
get_extents ("m", ex);
SI em= ex->x2 - ex->x1;
get_extents ("i", ex);
SI ei= ex->x2 - ex->x1;
bool mono= (em == ei);
sets the available common ligatures
// available standard ligatures
if (!mono) {
if (fnm->exists (0xfb00)) ligs += LIGATURE_FF;
if (fnm->exists (0xfb01)) ligs += LIGATURE_FI;
if (fnm->exists (0xfb02)) ligs += LIGATURE_FL;
if (fnm->exists (0xfb03)) ligs += LIGATURE_FFI;
if (fnm->exists (0xfb04)) ligs += LIGATURE_FFL;
if (fnm->exists (0xfb05)) ligs += LIGATURE_FT;
//if (fnm->exists (0xfb06)) ligs += LIGATURE_ST;
}
if (family == "Times New Roman")
ligs= LIGATURE_FI + LIGATURE_FL;
if (family == "Zapfino")
ligs= LIGATURE_FF + LIGATURE_FI + LIGATURE_FL + LIGATURE_FFI;
//cout << "ligs= " << ligs << ", " << family << ", " << size << "\n";
initialize the translation table for Unicode native glyphs for TeX Gyre fonts, which at the moment are the only ones with this particular feature implemented in TeXmacs,
// direct translations for certain characters without Unicode names
if (starts (family, "texgyre") && ends (family, "-math"))
tex_gyre_operators ();
and finally initialize micro-typographic adjustments (in lsub_correct, lsup_correct, ... fields of font_rep) which are hard-coded in TeXmacs for some of the “curated” fonts, for example:
if (starts (family, "STIX-")) {
if (!ends (family, "italic")) {
global_rsub_correct= (SI) (0.04 * wfn);
global_rsup_correct= (SI) (0.04 * wfn);
lsub_correct= lsub_stix_table ();
lsup_correct= lsup_stix_table ();
rsub_correct= rsub_stix_table ();
rsup_correct= rsup_stix_table ();
above_correct= above_stix_table ();
}
else {
global_rsub_correct= (SI) (0.04 * wfn);
global_rsup_correct= (SI) (0.04 * wfn);
lsub_correct= lsub_stix_italic_table ();
lsup_correct= lsup_stix_italic_table ();
rsub_correct= rsub_stix_italic_table ();
rsup_correct= rsup_stix_italic_table ();
above_correct= above_stix_italic_table ();
}
}
// other cases for TeX Gyre fonts, Papyrus, Linux Libertine & Biolinum, Fira, not shown
}
The tex_gyre_native function initialize lookup table to find entities (for mathematical typography) which are not mapped in the standardized unicode points but in the private areas and in a font-dependent manner. It might be interesting to see how it is coded to have an idea of the range of glyphs involved in the re-mapping:
static hashmap<string,int>
tex_gyre_native () {
static hashmap<string,int> native;
if (N(native) != 0) return native;
native ("<big-prod-2>")= 4215;
native ("<big-amalg-2>")= 4216;
native ("<big-sum-2>")= 4217;
native ("<big-int-2>")= 4149;
native ("<big-iint-2>")= 4150;
native ("<big-iiint-2>")= 4151;
native ("<big-iiiint-2>")= 4152;
native ("<big-oint-2>")= 4153;
native ("<big-oiint-2>")= 4154;
native ("<big-oiiint-2>")= 4155;
native ("<big-wedge-2>")= 3833;
native ("<big-vee-2>")= 3835;
native ("<big-cap-2>")= 3827;
native ("<big-cup-2>")= 3829;
native ("<big-odot-2>")= 3864;
native ("<big-oplus-2>")= 3868;
native ("<big-otimes-2>")= 3873;
native ("<big-pluscup-2>")= 3861;
native ("<big-sqcap-2>")= 3852;
native ("<big-sqcup-2>")= 3854;
native ("<big-intlim-2>")= 4149;
native ("<big-iintlim-2>")= 4150;
native ("<big-iiintlim-2>")= 4151;
native ("<big-iiiintlim-2>")= 4152;
native ("<big-ointlim-2>")= 4153;
native ("<big-oiintlim-2>")= 4154;
native ("<big-oiiintlim-2>")= 4155;
native ("<big-upint-2>")= 4149;
native ("<big-upiint-2>")= 4150;
native ("<big-upiiint-2>")= 4151;
native ("<big-upiiiint-2>")= 4152;
native ("<big-upoint-2>")= 4153;
native ("<big-upoiint-2>")= 4154;
native ("<big-upoiiint-2>")= 4155;
native ("<big-upintlim-2>")= 4149;
native ("<big-upiintlim-2>")= 4150;
native ("<big-upiiintlim-2>")= 4151;
native ("<big-upiiiintlim-2>")= 4152;
native ("<big-upointlim-2>")= 4153;
native ("<big-upoiintlim-2>")= 4154;
native ("<big-upoiiintlim-2>")= 4155;
native ("<large-sqrt-1>")= 4136;
native ("<large-sqrt-2>")= 4148;
native ("<large-sqrt-3>")= 4160;
native ("<large-sqrt-4>")= 4172;
native ("<large-sqrt-5>")= 4184;
native ("<large-sqrt-6>")= 4196;
|
bracket (native, "(", 1, 5, 3461, 22);
bracket (native, ")", 1, 5, 3462, 22);
bracket (native, "{", 1, 5, 3465, 22);
bracket (native, "}", 1, 5, 3466, 22);
bracket (native, "[", 1, 5, 3467, 22);
bracket (native, "]", 1, 5, 3468, 22);
bracket (native, "lceil", 1, 5, 3469, 22);
bracket (native, "rceil", 1, 5, 3470, 22);
bracket (native, "lfloor", 1, 5, 3471, 22);
bracket (native, "rfloor", 1, 5, 3472, 22);
bracket (native, "llbracket", 1, 5, 3473, 22);
bracket (native, "rrbracket", 1, 5, 3474, 22);
bracket (native, "langle", 1, 6, 3655, 4);
bracket (native, "rangle", 1, 6, 3656, 4);
bracket (native, "llangle", 1, 6, 3657, 4);
bracket (native, "rrangle", 1, 6, 3658, 4);
bracket (native, "/", 1, 6, 3742, 7);
bracket (native, "\\", 1, 6, 3743, 7);
bracket (native, "|", 1, 6, 3745, 7);
bracket (native, "||", 1, 6, 3746, 7);
native ("<wide-hat-0>")= 125;
native ("<wide-tilde-0>")= 126;
native ("<wide-breve-0>")= 128;
native ("<wide-check-0>")= 135;
wide (native, "breve", 1, 6, 3378, 10);
wide (native, "invbreve", 1, 6, 3380, 10);
wide (native, "check", 1, 6, 3382, 10);
wide (native, "hat", 1, 6, 3384, 10);
wide (native, "tilde", 1, 6, 3386, 10);
wide (native, "overbrace", 0, 5, 3453, 22);
wide (native, "overbrace*", 0, 5, 3453, 22);
wide (native, "underbrace", 0, 5, 3454, 22);
wide (native, "underbrace*", 0, 5, 3454, 22);
wide (native, "poverbrace", 0, 5, 3455, 22);
wide (native, "poverbrace*", 0, 5, 3455, 22);
wide (native, "punderbrace", 0, 5, 3456, 22);
wide (native, "punderbrace*", 0, 5, 3456, 22);
wide (native, "sqoverbrace", 0, 5, 3457, 22);
wide (native, "sqoverbrace*", 0, 5, 3457, 22);
wide (native, "squnderbrace", 0, 5, 3458, 22);
wide (native, "squnderbrace*", 0, 5, 3458, 22);
return native;
}
|
The dispatching function is
unsigned int
unicode_font_rep::read_unicode_char (string s, int& i) {
if (s[i] == '<') {
i++;
int start= i, n= N(s);
while (true) {
if (i == n) {
i= start;
return (int) '<';
}
if (s[i] == '>') break;
i++;
}
if (s[start] == '#') {
start++;
return (unsigned int) from_hexadecimal (s (start, i++));
}
else {
string ss= s (start-1, ++i);
string uu= strict_cork_to_utf8 (ss);
if (uu == ss) {
if (native->contains (ss)) return 0xc000000 + native[ss];
return 0;
}
int j= 0;
return decode_from_utf8 (uu, j);
}
}
else {
unsigned int c= (unsigned int) s[i++];
if (c >= 32 && c <= 127) return c;
string ss= s (i-1, i);
string uu= strict_cork_to_utf8 (ss);
int j= 0;
return decode_from_utf8 (uu, j);
}
}
which maps entities of the form <#XXXX> in the Unicode code point XXXX, while tries to use the strict_cork_to_utf8 function to map other entities into a meaningful Unicode code point and if this fails check the native lookup table for possible glyph indexes and return a “fake” unicode point of the form 0xc000000 + glyph_index. The function decode_from_utf8 converts UTF8 into a unsigned int Unicode point.
This function is used by supports:
bool
unicode_font_rep::supports (string c) {
if (N(c) == 0) return false;
int i= 0;
unsigned int uc= read_unicode_char (c, i);
if (uc == 0 || !fnm->exists (uc)) return false;
if (uc >= 0x42 && uc <= 0x5a && !fnm->exists (0x41)) return false;
if (uc >= 0x62 && uc <= 0x7a && !fnm->exists (0x61)) return false;
metric_struct* m= fnm->get (uc);
return m->x1 < m->x2 && m->y1 < m->y2;
}
Note that fnm->exists (uc) refers to
bool tt_font_metric_rep::exists (int i);
which uses decode_index to retrieve the glyph number (and decode the “fake” unicode points into direct glyph numbers)
inline FT_UInt
decode_index (FT_Face face, int i) {
if (i < 0xc000000) return ft_get_char_index (face, i);
return i - 0xc000000;
}
Ligature replacement is implemented as follow
unsigned int
unicode_font_rep::ligature_replace (unsigned int uc, string s, int& i) {
int n= N(s);
if (((char) uc) == 'f') {
if (i<n && s[i] == 'i' && (ligs & LIGATURE_FI) != 0) {
i++; return 0xfb01; }
else if (i<n && s[i] == 'l' && (ligs & LIGATURE_FL) != 0) {
i++; return 0xfb02; }
else if (i<n && s[i] == 't' && (ligs & LIGATURE_FT) != 0) {
i++; return 0xfb05; }
else if ((i+1)<n && s[i] == 'f' && s[i+1] == 'i' &&
(ligs & LIGATURE_FFI) != 0) {
i+=2; return 0xfb03; }
else if ((i+1)<n && s[i] == 'f' && s[i+1] == 'l' &&
(ligs & LIGATURE_FFL) != 0) {
i+=2; return 0xfb04; }
else if (i<n && s[i] == 'f' && (ligs & LIGATURE_FF) != 0) {
i++; return 0xfb00; }
else return uc;
}
else if (((char) uc) == 's') {
if (i<n && s[i] == 't' && (ligs & LIGATURE_ST) != 0) {
i++; return 0xfb06; }
else return uc;
}
else return uc;
}
All these mechanisms works together in virtual methods like draw_fixed to produce a series of glyphs on the rendering surface via the draw method of render_rep:
void renderer_rep::draw (int c, font_glyphs fng, SI x, SI y)
specifically the code of unicode_font_rep::draw_fixed reads:
void
unicode_font_rep::draw_fixed (renderer ren, string s, SI x, SI y, bool ligf) {
int i= 0, n= N(s);
unsigned int uc= 0xffffffff;
while (i<n) {
unsigned int pc= uc;
uc= read_unicode_char (s, i);
if (ligs > 0 && ligf && (((char) uc) == 'f' || ((char) uc) == 's'))
uc= ligature_replace (uc, s, i);
if (pc != 0xffffffff) x += ROUND (fnm->kerning (pc, uc));
ren->draw (uc, fng, x, y);
metric_struct* ex= fnm->get (uc);
x += ROUND (ex->x2);
//if (fnm->kerning (pc, uc) != 0)
//cout << "Kerning " << ((char) pc) << ((char) uc) << " " << ROUND (fnm->kerning (pc, uc)) << ", " << ROUND (ex->x2) << "\n";
}
}
Rubber Unicode fonts are implemented similarly to rubber fonts. They dispatch according to the search_font function which caches the subfont index and rewriting returned by search_font_sub:
int
rubber_unicode_font_rep::search_font_sub (string s, string& rew) {
if (starts (s, "<big-") && ends (s, "-1>")) {
string r= s (5, N(s) - 3);
if (ends (r, "lim")) r= r (0, N(r) - 3);
if (starts (r, "up")) r= r (2, N(r));
r= "<" * r * ">";
if (base->supports (r)) {
rew= r;
if (r == "<sum>" || r == "<prod>" || ends (r, "int>"))
if (big_sums) return 0;
return 2;
}
}
if (starts (s, "<big-") && ends (s, "-2>")) {
if (big_flag && base->supports (s)) {
rew= s;
return 0;
}
string r= s (5, N(s) - 3);
if (ends (r, "lim")) r= r (0, N(r) - 3);
if (starts (r, "up")) r= r (2, N(r));
if (big_flag && base->supports ("<big-" * r * "-1>")) {
rew= "<big-" * r * "-1>";
return 2;
}
r= "<" * r * ">";
if (base->supports (r)) {
rew= r;
if (r == "<sum>" || r == "<prod>" || ends (r, "int>"))
if (big_sums) return 2;
return 3;
}
}
if (starts (s, "<mid-")) s= "<left-" * s (5, N(s));
if (starts (s, "<right-")) s= "<left-" * s (7, N(s));
if (starts (s, "<large-")) s= "<left-" * s (7, N(s));
if (starts (s, "<left-")) {
int pos= search_backwards ("-", N(s), s);
if (pos > 6) {
if (s[pos-1] == '-') pos--;
string r= s (6, pos);
if (r == ".") { rew= ""; return 0; }
if ((r == "(" && base->supports ("<#239C>")) ||
(r == ")" && base->supports ("<#239F>")) ||
(r == "[" && base->supports ("<#23A2>")) ||
(r == "]" && base->supports ("<#23A5>")) ||
((r == "{" || r == "}") && base->supports ("<#23AA>")) ||
(r == "sqrt" && base->supports ("<#23B7>"))) {
rew= s;
return 4;
}
rew= r;
if (N(rew) > 1) rew= "<" * rew * ">";
if (ends (s, "-0>")) return 0;
return 0;
}
}
rew= s;
return 0;
}
There are 5 subfonts which are instantiated as follows:
font
rubber_unicode_font_rep::get_font (int nr) {
ASSERT (nr < N(subfn), "wrong font number");
if (initialized[nr]) return subfn[nr];
initialized[nr]= true;
switch (nr) {
case 0:
break;
case 1:
subfn[nr]= base->magnify (sqrt (0.5));
break;
case 2:
subfn[nr]= base->magnify (sqrt (2.0));
break;
case 3:
subfn[nr]= base->magnify (2.0);
break;
case 4:
subfn[nr]= rubber_assemble_font (base);
break;
}
return subfn[nr];
}
and are given by progressively zoomed versions of the base font plus an additional rubber_assemble_font used to create synthetic rubber from pieces of the base Unicode font. Its implementation is relatively straightforward: for the first few sizes it uses magnified variants of the base font:
#define MAGNIFIED_NUMBER 4
font
rubber_assemble_font_rep::get_font (int nr) {
ASSERT (nr < N(larger), "wrong font number");
if (initialized[nr]) return larger[nr];
initialized[nr]= true;
larger[nr]= base->magnify (pow (2.0, ((double) nr) / 4.0));
return larger[nr];
}
while for larger variants it uses the virtual glyphs described in the "emu-alt-large" virtual font according to the following dispatching search_font function:
int
rubber_assemble_font_rep::search_font (string s, string& r) {
if (starts (s, "<mid-")) s= "<left-" * s (5, N(s));
if (starts (s, "<right-")) s= "<left-" * s (7, N(s));
if (starts (s, "<large-")) s= "<left-" * s (7, N(s));
if (starts (s, "<left-")) {
int pos= search_backwards ("-", N(s), s);
if (pos > 6) {
if (s[pos-1] == '-') pos--;
r= s (6, pos);
int num= as_int (s (pos+1, N(s)-1));
int nr= num - 5;
int code;
if (num <= MAGNIFIED_NUMBER) return num;
else if (r == "(")
code= virt->dict ["<rubber-lparenthesis-#>"];
else if (r == ")")
code= virt->dict ["<rubber-rparenthesis-#>"];
else if (r == "[")
code= virt->dict ["<rubber-lbracket-#>"];
else if (r == "]")
code= virt->dict ["<rubber-rbracket-#>"];
else if (r == "{")
code= virt->dict ["<rubber-lcurly-#>"];
else if (r == "}")
code= virt->dict ["<rubber-rcurly-#>"];
else if (r == "lfloor")
code= virt->dict ["<rubber-lfloor-#>"];
else if (r == "rfloor")
code= virt->dict ["<rubber-rfloor-#>"];
else if (r == "lceil")
code= virt->dict ["<rubber-lceil-#>"];
else if (r == "rceil")
code= virt->dict ["<rubber-rceil-#>"];
else if (r == ".")
code= virt->dict ["<rubber-nosymbol-#>"];
else if (r == "nosymbol")
code= virt->dict ["<rubber-nosymbol-#>"];
else if (r == "|")
code= virt->dict ["<rubber-bar-#>"];
else if (r == "||")
code= virt->dict ["<rubber-parallel-#>"];
else if (r == "interleave")
code= virt->dict ["<rubber-interleave-#>"];
else if (r == "sqrt")
code= virt->dict ["<rubber-sqrt-#>"];
else
code= virt->dict ["<rubber-lparenthesis-#>"];
r= string ((char) code) * as_string (nr) * ">";
return MAGNIFIED_NUMBER + 1;
}
}
r= s;
return 0;
}
Virtual fonts provide a mechanism to extend the set of available glyphs by synthesizing new glyphs from operations on those of a base font. The programs which describe the sequence of (parametrized) operations to perform are formulated in a domain-specific language of s-expressions.
The main entry point is the function
font virtual_font (font base, string name, int size, int hdpi, int vdpi, bool extend);
The extend flag allows to control if the virtual font behaves as an overlay over the base font allowing to access the base-defined glyphs or not.
Virtual fonts definitions are collected in the $TEXMACS_PATH/fonts/virtual directory with suffix .vfn. As an example of the DSL, here the emu-bracket.vfn font which describes the synthetic large brackets:
(virtual-font
(emu-backslash (hor-flip /))
(emu-tslash (unindent (crop (part (crop /) * * 0.5 *))))
(emu-tbackslash (hor-flip emu-tslash))
(emu-bslash (unindent (crop (part (crop /) * * * 0.5))))
(emu-bbackslash (hor-flip emu-bslash))
(emu-langle-pre (unindent (join (unindent emu-bbackslash)
(unindent emu-tslash))))
(emu-rangle-pre (unindent (join (unindent* emu-bslash)
(unindent* emu-tbackslash))))
(emu-langle-bis (with sc (/ (height (crop [)) (height emu-langle-pre))
(align* (magnify emu-langle-pre * sc) [ * 0.5)))
(emu-rangle-bis (with sc (/ (height (crop ])) (height emu-rangle-pre))
(align* (magnify emu-rangle-pre * sc) ] * 0.5)))
(emu-langle (unindent (enlarge emu-langle-bis 0.1 0.1 0 0)))
(emu-rangle (unindent (enlarge emu-rangle-bis 0.1 0.1 0 0)))
(emu-llangle (join (0 0 emu-langle) (0.2 0 emu-langle)))
(emu-rrangle (join (0 0 emu-rangle) (0.2 0 emu-rangle)))
(emu-lfloor (join (part [ * * * 0.5) (part [ * * 0.25 0.75 0 0.25)))
(emu-rfloor (join (part ] * * * 0.5) (part ] * * 0.25 0.75 0 0.25)))
(emu-lceil (join (part [ * * 0.5 *) (part [ * * 0.25 0.75 0 -0.25)))
(emu-rceil (join (part ] * * 0.5 *) (part ] * * 0.25 0.75 0 -0.25)))
(emu-dlbracket (glue [ [))
(emu-drbracket (glue ] ]))
(emu-dlfloor (join (part emu-dlbracket * * * 0.5)
(part emu-dlbracket * * 0.25 0.75 0 0.25)))
(emu-drfloor (join (part emu-drbracket * * * 0.5)
(part emu-drbracket * * 0.25 0.75 0 0.25)))
(emu-dlceil (join (part emu-dlbracket * * 0.5 *)
(part emu-dlbracket * * 0.25 0.75 0 -0.25)))
(emu-drceil (join (part emu-drbracket * * 0.5 *)
(part emu-drbracket * * 0.25 0.75 0 -0.25)))
(emu-tlbracket (glue [ emu-dlbracket))
(emu-trbracket (glue ] emu-drbracket))
(emu-tlfloor (join (part emu-tlbracket * * * 0.5)
(part emu-tlbracket * * 0.25 0.75 0 0.25)))
(emu-trfloor (join (part emu-trbracket * * * 0.5)
(part emu-trbracket * * 0.25 0.75 0 0.25)))
(emu-tlceil (join (part emu-tlbracket * * 0.5 *)
(part emu-tlbracket * * 0.25 0.75 0 -0.25)))
(emu-trceil (join (part emu-trbracket * * 0.5 *)
(part emu-trbracket * * 0.25 0.75 0 -0.25)))
(emu-dbar (join #7C (part #7C * * * * 0.6 0)))
(emu-tbar (join #7C (part #7C * * * * 0.6 0)
(part #7C * * * * 1.2 0))))
As we see the file is composed by a single S-expression with head virtual-font and a sequence of glyph definitions in the form (glyph-name glyph-code). The code itself is composed recursively by operators with arguments given by further subexpressions.
One of the interpreters of the language is draw_tree:
void virtual_font_rep::draw_tree (renderer ren, scheme_tree t, SI x, SI y);
The code expressions are evaluated as follows. We indicate with a dollar-prefixed label like $val variables which match subexpressions in the templates.
An atomic value (not a list) refers to a glyph in the base font or to another virtual glyph.
A list of the form ($x $y $s) where $x, $y are floating-point numbers and $s a symbol, evaluate in the glyph associated to $s and shifted according to the pair $x, $y.
(with $var $val $body) evaluates $body with the symbol $var replaced by the value of the expression $val.
(or $el1 $el2 ...) evaluates in the first valid expression in the list (as determined by the supported method)
(join $el1 $el2 ...) evaluates in the superposition of the result of all the expressions, in sequence, in the list;
(intersect $glyph1 $glyph2), (exclude $glyph1 $glyph2) compose glyph bitmaps with raster operators
(bitmap $glyph) evaluates in the result of $s;
(glue $glyph1 $glyph2), (glue* $glyph1 $glyph2) glue virtual glyphs horizontally with different alignments
(glue-above $glyph1 $glyph2 $dy), (glue-below $glyph1 $glyph2 $dy) glue glyphs vertically with an optional shift
In the following we list most of the other available operators, for details on their meaning please refer to the source code of virtual_font_rep.
(row $e1 $e2)
(stack $glyph1 $glyph2 $e3), (stack-equal $glyph1 $glyph2 $e3), (stack-less $glyph1 $glyph2 $e3)
(right-fit $glyph1 $glyph2 $e3), (left-fit $glyph1 $glyph2 $e3)
(add $glyph1 $glyph2)
(magnify $e1 $e2 $e3)
(enlarge $e1)
(unindent $e1), (unindent* $e1)
(crop $e1), (hor-crop $e1), (ver-crop $e1), (left-crop $e1),(right-crop $e1), (top-crop $e1), (bottom-crop $e1)
(clip $glyph $x1 $y1 $x2 $y2)
(part $glyph $x1 $y1 $x2 $y2 $dx $dy)
(copy $e1)
(hor-flip $e1), (ver-flip $e1), (rot-left $e1), (rot-right $e1)
(rotate $glyph $angle $xf $yf)
(hor-extend $glyph $xx $yy $zz), (ver-extend $glyph $xx $yy $zz)
(ver-take $glyph $xx $yy $zz)
(align $glyph $xx $yy), (align* $glyph $xx $yy)
(scale $glyph1 $glyph2 $sx $sy), (scale* $glyph1 $glyph2 $sx $sy)
(hor-scale $glyph1 $glyph2)
(pretend $glyph1 $glyph2), (hor-pretend $glyph1 $glyph2), (left-pretend $glyph1 $glyph2), (right-pretend $glyph1 $glyph2), (ver-pretend $glyph1 $glyph2)
(relash $glyph1 $glyph2)
(negate $glyph1 $glyph2)
(min-width $glyph1 $glyph2), (max-width $glyph1 $glyph2), (min-height $glyph1 $glyph2), (max-height $glyph1 $glyph2)
(font $p1 $p2 $p3 …)
(italic $p1 $p2 $p3)
(circle $r $w)
TeX fonts are physical fonts are handled via specific mechanisms which decoded the TeX font files and metrics to produce metric informations for the typesetter and bitmaps for the renderer. They work similarly to Unicode fonts, but the specifics of the encoding of the various TeXmacs entities is complex due to the limitations in the design of the font files and a logical font must be reconstructed gluing together several physical fonts and taking care of rubber, mathematical alphabets, etc...
The math_font class represent a compound font which can render all the usual entities for mathematical document preparation. It is modeled around TeX math fonts to map several physical fonts to cover all math alphabets.
As we already discusses, TeXmacs implements a font substitution mechanism that tries to find a physical font which better fits a given series of characteristics. This is used to find replacements for missing features (like a bold alphabet, or upright Greek letters, etc...) or glyph sets (e.g. Greek, Cyrillic, asian fonts, mathematical letters, mathematical symbols)
The entrypoint of this system is the function
font closest_font (string family, string variant, string series, string shape,
int sz, int dpi, int attempt)
which returns a physical font which fits certain characteristics (i.e. family, variant, series, shape). The attempt variable is used to iterate among the possible return values according to the order given by a distance function defined among all fonts. The function closest_font calls find_closest to do caching and the actual search of a physical font with suitable characteristics:
bool
find_closest (string& family, string& variant, string& series, string& shape,
int attempt) {
static hashmap<tree,tree> closest_cache (UNINIT);
tree val= tuple (copy (family), variant, series, shape);
tree key= tuple (copy (family), variant, series, shape, as_string (attempt));
if (closest_cache->contains (key)) {
tree t = closest_cache[key];
family = t[0]->label;
variant= t[1]->label;
series = t[2]->label;
shape = t[3]->label;
return t != val;
}
else {
//cout << "< " << family << ", " << variant
// << ", " << series << ", " << shape << "\n";
array<string> lfn= logical_font (family, variant, series, shape);
lfn= apply_substitutions (lfn);
array<string> pfn= search_font (lfn, attempt);
array<string> nfn= logical_font (pfn[0], pfn[1]);
array<string> gfn= guessed_features (pfn[0], pfn[1]);
//cout << lfn << " -> " << pfn << ", " << nfn << ", " << gfn << "\n";
gfn << nfn;
family= get_family (nfn);
variant= get_variant (nfn);
series= get_series (nfn);
shape= get_shape (nfn);
if ( contains (string ("outline"), lfn) &&
!contains (string ("outline"), gfn))
variant= variant * "-poorbbb";
if ( contains (string ("bold"), lfn) &&
!contains (string ("bold"), gfn))
series= series * "-poorbf";
if ( contains (string ("smallcaps"), lfn) &&
!contains (string ("smallcaps"), gfn))
shape= shape * "-poorsc";
if ((contains (string ("italic"), lfn) ||
contains (string ("oblique"), lfn)) &&
!contains (string ("italic"), gfn) &&
!contains (string ("oblique"), gfn))
shape= shape * "-poorit";
//cout << "> " << family << ", " << variant
// << ", " << series << ", " << shape << "\n";
tree t= tuple (family, variant, series, shape);
closest_cache (key)= t;
return t != val;
}
}
As we see, this function uses search_font to determine available fonts with similar characteristics (as specified by logical_font and after performing some substitutions via apply_substitutions). If the selected font does not posses features (outline, bold, smallcaps, italic) of the required font, we synthesize them via “poor” replacements.
Font substitutions are collected in the file $TEXMACS_PATH/fonts/font-substitutions.scm whose format is a list of Scheme expressions like
((Bodoni\ 72 smallcaps) (Bodoni\ 72\ Smallcaps)) ((Bodoni\ 72\ Oldstyle smallcaps) (Bodoni\ 72\ Smallcaps)) ((Linux\ Libertine sansserif) (Linux\ Biolinum)) ((TeX\ Gyre\ Pagella typewriter) (roman typewriter)) ((Calibri typewriter) (Consolas)) ((Cambria sansserif) (Calibri)) ((Cambria typewriter) (Consolas)) ((Constantia sansserif) (Corbel)) ((Constantia typewriter) (Consolas)) ((Corbel typewriter) (Consolas))
which specify replacement families for a given combination of family and feature of a logical font. For example the correct sansserif version of Linux Libertine is Linux Biolinum, etc...
The other important configuration files which control the selection of physical fonts are font-features.scm, font-database.scm and font-characteristics.scm all located in the folder $TEXMACS_PATH/fonts. These are computer generated and cache several important informations obtained by analyzing the available font files, those local to the specific installation of TeXmacs are kept in $TEXMACS_HOME_PATH/fonts.
The file font-database.scm associate to each font identifier a the filename and a subfont number:
((TeXmacs\ Computer\ Modern\ Sans Bold) ((ecsx10.tfm 0 3132))) ((TeXmacs\ Computer\ Modern\ Sans Bold\ Condensed) ((ecssdc10.tfm 0 3128))) ((TeXmacs\ Computer\ Modern\ Sans Bold\ Flat) ((eclb10.tfm 0 3584))) ((TeXmacs\ Computer\ Modern\ Sans Bold\ Italic\ Flat) ((eclo10.tfm 0 3584))) ((TeXmacs\ Computer\ Modern\ Sans Bold\ Oblique) ((ecso10.tfm 0 3352))) ((TeXmacs\ Computer\ Modern\ Sans Flat) ((eclq10.tfm 0 3584))) ((TeXmacs\ Computer\ Modern\ Sans Italic\ Flat) ((ecli10.tfm 0 3584))) ((TeXmacs\ Computer\ Modern\ Sans Oblique) ((ecsi10.tfm 0 3360))) ((TeXmacs\ Computer\ Modern\ Sans Regular) ((ecss10.tfm 0 3140))) ((TeXmacs\ Concrete Bold) ((ecbx10.tfm 0 3200))) ((TeXmacs\ Concrete Bold\ Condensed) ((ecrb10.tfm 0 3196))) ((TeXmacs\ Concrete Bold\ Italic) ((ecbi10.tfm 0 2900))) ((TeXmacs\ Concrete Bold\ Oblique) ((ecbl10.tfm 0 3412)))
The file font-features.scm records the available features for each font identifier, for example:
(Tangerine Tangerine Italic ArtPen Calligraphic) (Telugu\ MN Telugu\ MN) (Telugu\ Sangam\ MN Telugu\ Sangam\ MN SansSerif) (Tempora Tempora) (TeX\ AMS\ Blackboard\ Bold Bbb Outline) (TeX\ Bard bard Ancient) (TeX\ Blackboard\ Bold Bbb* Outline) (TeX\ Blackboard\ Bold\ Sans Bbb* SansSerif Outline) (TeX\ Blackboard\ Bold\ Variant Bbb** Outline) (TeX\ Blackletter blackletter Ancient Gothic) (TeX\ Calligraphic calligraphic Italic ArtPen Attached Calligraphic) (TeX\ Calligraphic\ Capitals cal Calligraphic)
While the font-characteristics.scm file records several attributes associated to each font, which are used to determine similar-looking fonts and their relative distance:
((TeX\ Gothic Regular) (mono=no sans=no slant=17 italic=no case=mixed regular=no ex=83 em=187 lvw=27 lhw=19 uvw=15 uhw=144 fillp=40 vcnt=47 lasprat=66 pasprat=65 loasc=134 lodes=139 dides=104)) ((TeX\ Gyre\ Adventor Bold) (Ascii Latin Greek mono=no sans=yes slant=0 italic=no case=mixed regular=yes ex=92 em=163 lvw=23 lhw=21 uvw=25 uhw=23 fillp=56 vcnt=62 lasprat=99 pasprat=85 loasc=139 lodes=140 dides=102)) ((TeX\ Gyre\ Adventor Bold\ Italic) (Ascii Latin Greek mono=no sans=yes slant=18 italic=no case=mixed regular=yes ex=92 em=163 lvw=23 lhw=21 uvw=23 uhw=23 fillp=48 vcnt=56 lasprat=99 pasprat=97 loasc=139 lodes=140 dides=102)) ((TeX\ Gyre\ Adventor Italic) (Ascii Latin Greek mono=no sans=yes slant=20 italic=no case=mixed regular=yes ex=91 em=168 lvw=14 lhw=12 uvw=14 uhw=12 fillp=30 vcnt=35 lasprat=99 pasprat=95 loasc=135 lodes=139 dides=102)) ((TeX\ Gyre\ Adventor Regular) (Ascii Latin Greek mono=no sans=yes slant=0 italic=no case=mixed regular=yes ex=91 em=168 lvw=13 lhw=12 uvw=13 uhw=12 fillp=36 vcnt=38 lasprat=99 pasprat=83 loasc=135 lodes=139 dides=102)) ((TeX\ Gyre\ Bonum Bold) (Ascii Latin Greek mono=no sans=no slant=0 italic=no case=mixed regular=yes ex=84 em=186 lvw=35 lhw=19 uvw=38 uhw=20 fillp=55 vcnt=60 lasprat=115 pasprat=110 loasc=152 lodes=148 dides=102))
An alternative font selection mechanism, active in particular when new_fonts is false, is a macro-based
font-selection scheme (using the
(tex $name $size $dpi)
corresponds to the constructor
font tex_font (display dis, string fam, int size, int dpi, int dsize=10);
of a TeX text font.
At the middle level, it is possible to specify some rewriting rules like
((roman rm medium right $s $d) (ec ecrm $s $d)) ((avant-garde rm medium right $s $d) (tex rpagk $s $d 0)) ((x-times rm medium right $s $d) (ps adobe-times-medium-r-normal $s $d))
When a left hand pattern is matched, it is recursively substituted by the right hand side. The files in the directory progs/fonts contain a large number of rewriting rules.
At the top level, TeXmacs calls (via the find_font function) a macro of the form
($name $family $series $shape $size $dpi)
as a function of the current environment in the text.

